Synchronization1: Concurrency and Mutual Exclusion
1. Recall && Intro
1.1 Goals for Today: Synchronization
操作系统如何通过线程提供并发性?
- 对进程/线程状态和调度进行简要讨论
- 高级讨论如何通过堆栈实现并发性
引入同步需求
讨论锁和信号量(Locks and Semaphores)
操作系统通过创建、管理和调度线程来实现并发。每个线程都有自己独立的执行路径,但在同一进程中的多个线程可以共享资源,比如内存空间。因此,通过有效地管理和调度这些线程,操作系统可以使多个任务同时进行。
进程/线程状态包括新建、就绪、运行、等待(阻塞)和完成等。调度器根据特定策略(例如轮转法、优先级调度法等)从就绪队列中选择一个进程或线程分配给CPU。
堆栈对于并发性非常重要。每个线程都有自己独立的堆栈,用于存储局部变量以及跟踪函数调用和返回地址。由于每个线程都有自己独立的堆栈,所以它们可以独立地执行不同的任务。
同步是必要的因为多个并发运行的线程可能需要共享数据或者资源。如果没有适当地控制对共享资源的访问,则可能会导致数据不一致或其他问题。
锁(Locks)和信号量(Semaphores)是两种常见且基础的同步机制。锁通常用于保护临界区域只能被一个线程在任意时刻访问;而信号量则更加通用,并可用来控制对一组资源(而非单一资源)或者协助多个进程/线程序列化相关操作。
1.2 Multiplexing Processes: The Process Control Block(多路复用进程:进程控制块)
内核使用所谓的进程控制块(Process Control Block,PCB)来表示每一个进程。这是一种数据结构,其中包含了关于进程的重要信息。
- 状态(例如运行中、就绪、阻塞等):这描述了进程在其生命周期中的当前阶段。
- 寄存器状态(当不处于就绪状态时):当进程被挂起时,它的寄存器状态会被保存下来,以便稍后恢复执行。
- 进程ID (PID),用户,可执行文件,优先级等:这些都是描述或者影响进程行为的属性。
- 执行时间等:用于计算和跟踪进程使用CPU的时间量。
- 内存空间、地址转换等:与该程序分配和使用内存有关的信息。
内核调度器维护一个包含所有PCB的数据结构。
- 调度器根据特定策略决定将CPU分配给哪个线程或者进程进行处理。例如,在轮询调度策略中,每个可运行线程将依次获得固定时间片进行处理。
分配非CPU资源如内存和IO设备也是根据某种策略决定。
- 例如,在内存管理方面, 可能采取页面置换算法如LRU(Least Recently Used) 或者FIFO(First In First Out) 来决定当内存不足时应替换出哪个页面。
1.3 Context Switch
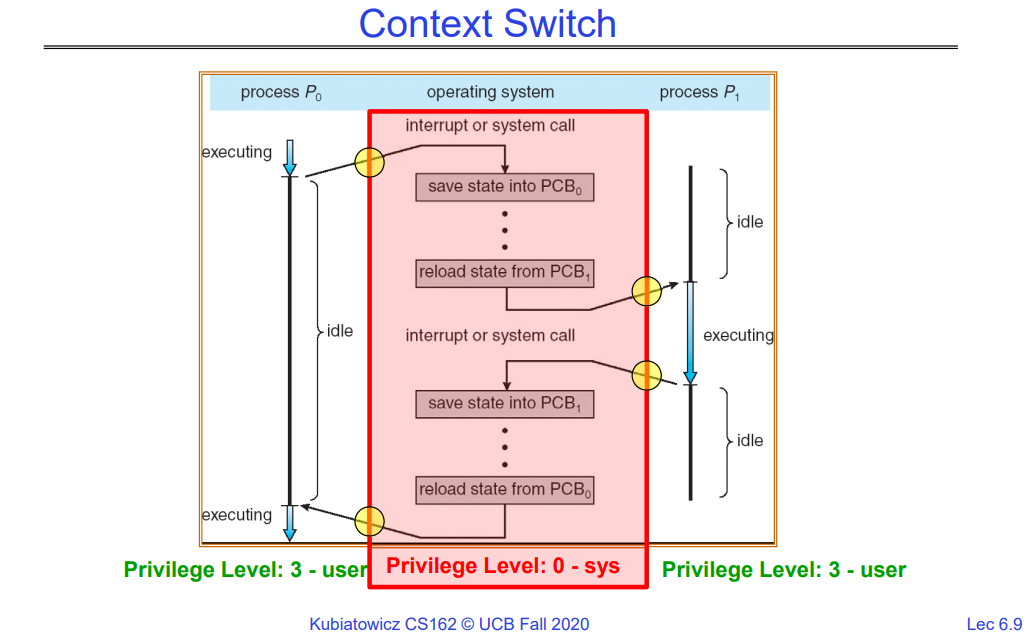
进程的上下文切换,本质上是通过切换PCB的内容来实现进程调度。每一次进程调度都需要两次状态切换操作,因此要控制好进程切换的频率。
在许多操作系统中,特权级别用于区分不同的运行环境,以此来保护系统的关键部分免受恶意或误操作的影响。以下是两个常见的特权级别:
- 特权级别0(Privilege Level 0):也被称为系统级(system level),内核级(kernel level)或超级用户模式(supervisor mode)。这是最高的特权级别。在这个模式下,代码可以直接访问所有硬件资源和内存,并可以执行任何CPU指令。操作系统内核通常在这个模式下运行。
- 特权级别3(Privilege Level 3):也被称为用户级(user level)。在这个模式下,代码的权限较低,不能直接访问硬件或执行某些CPU指令。大部分用户程序,在这个模式下运行。
还有介于0和3之间的状态,同理他们的权限也介于用户态和内核态之间,但是不怎么常用,我们常用的是0和3这两个特权级别。
1.4 Lifecycle of a Process or Thread
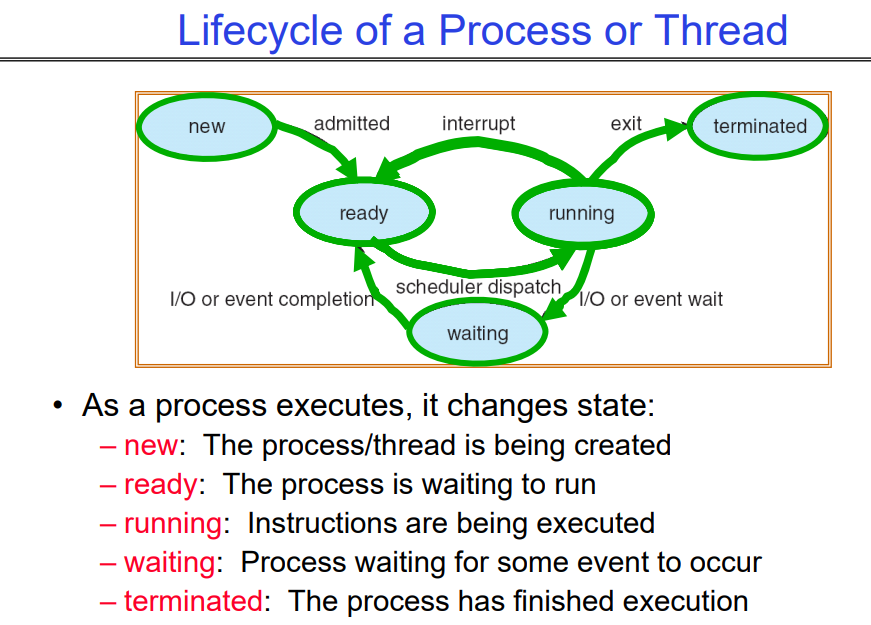
随着进程的执行,它会改变状态:
- 新建(new):进程/线程正在被创建。
- 就绪(ready):进程已准备好运行,等待调度器将其分配给CPU。
- 运行(running):正在执行指令。在这个状态下,进程被操作系统选中并赋予CPU时间进行处理。
- 等待/阻塞(waiting/blocking):进程正在等待某些事件发生,例如等待I/O操作完成或者等待某个信号量。在此状态下,即使CPU是空闲的,该进程也不会被执行。此时该进程将被放入waiting list,让出处理器。
- 终止/完成(terminated/done):进程已经结束执行。这可能是因为它已经完成了其任务、因为它由于错误而崩溃或者因为它被其他的一些过程明确地杀死。
注意,当一个进程处于terminated状态时,他就是一个zombie进/线程,直到它的父进程得到了该进程的执行结果后,这个僵尸进程就可以被释放了。
注意这是针对一个核的调度图,如果我们有多个核的话,会有多个这样的调度队列存在,每个核会负责一部分进程或线程的执行,但是注意一个线程不可能在同时在多个核上执行,因为他只有一个栈。
1.5 Scheduling: All About Queues
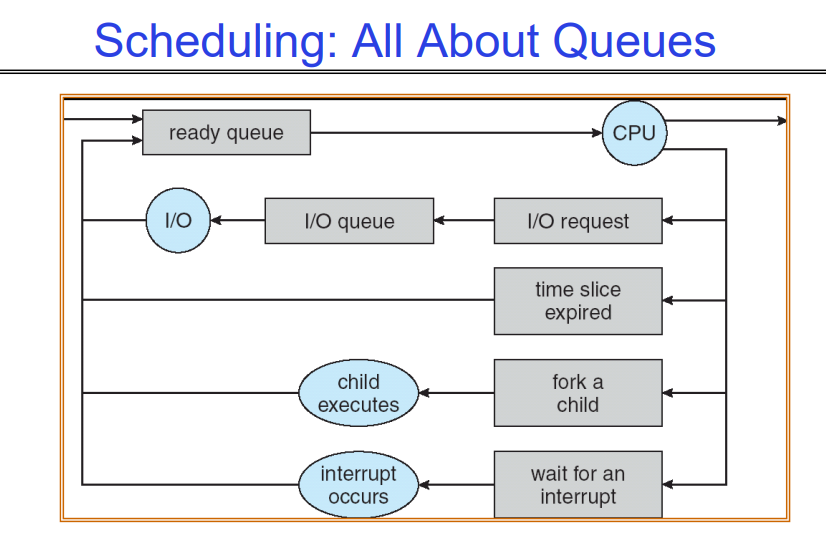
这是内核中维护的各种队列,PCB会在这些队列之间来回移动,CPU代表的是running process,剩下的也很好理解,之后将会更深入的讨论这个话题。
1.6 Ready Queue And Various I/O Device Queues
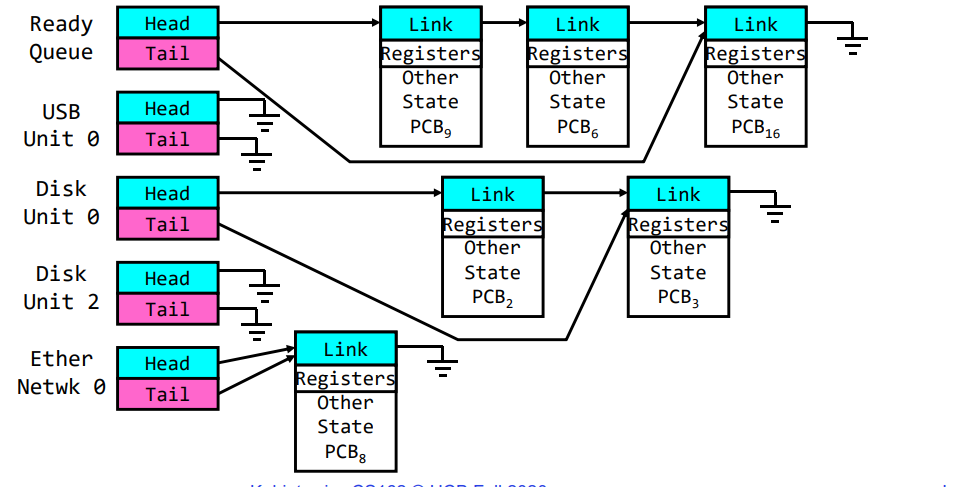
进程不在运行 -> 这意味着PCB在某个调度器队列中:
- 当进程不在运行状态时(例如,它可能是新建的、就绪的、等待的或已完成的),其进程控制块(PCB)会存在于相应的调度器队列中。
每个设备/信号/条件都有单独的队列:
- 为了有效地管理系统资源,操作系统通常会为每种类型的设备、信号或条件维护一个单独的队列。
- 例如,可能会有一个用于管理等待磁盘I/O操作完成的进程的队列,另一个用于管理等待网络数据到达的进程的队列。
每个队列可以有不同的调度策略:
- 尽管所有这些都是调度器队列,但并非所有这些队列都需要使用相同类型或参数设置进行调度。
- 例如,在处理CPU密集型任务和I/O密集型任务时,可能需要使用不同类型和参数设置进行优化。根据当前任务重点关注的内容:如公平性、实时性保证、延迟优化等等,去选择不同的策略。
1.7 Recall: Single and Multithreaded Processes
线程封装并发性:“活动”组件:
- 线程是操作系统中最小的执行单元,它们在同一个进程中共享资源(如内存空间),但各自拥有独立的运行状态。这使得在同一个进程中的多个线程可以并发执行,从而提高程序的效率。
地址空间封装保护:“被动”部分:
- 地址空间是进程在内存中的区域,它为进程和其数据提供了保护。通过将每个进程隔离在自己的地址空间中,操作系统可以防止错误或恶意的程序破坏系统或其他进程。
为什么每个地址空间要有多个线程?这主要有以下几点原因:
- 提高并发性:在同一地址空间(即同一进程)下运行多个线程可以提高应用程序的并发性。因为这些线程共享相同的内存和资源,所以它们之间进行通信比不同进程之间进行通信更快、更简单。
- 提高效率:如果一个应用需要处理大量I/O操作或者等待外部事件完成时,使用多线程可以使CPU不会闲置。当一个线程等待I/O完成时,其他线程还可以继续执行。
- 更好地利用多核处理器:如果你有一个具有多核心处理器的系统,并且你希望你的应用能够充分利用所有核心,则使用多线程是非常必要的。每个核心都能够独立地运行一个单独的线程序列化相关操作。
总结起来说,在一般情况下,每个地址空间(即每个进程)都会有多个线程序列化相关操作主要是为了实现更好地并发性、效率和资源利用率。
1.8 The Core of Concurrency: the Dispatch Loop
从概念上讲,操作系统的调度循环如下所示:
Loop {
RunThread(); // 运行线程
ChooseNextThread(); // 选择下一个线程
SaveStateOfCPU(curTCB); // 保存当前CPU状态(即当前线程控制块,TCB)
LoadStateOfCPU(newTCB); // 加载新的CPU状态(即新的线程控制块,TCB)
}
这是一个无限循环。
- 可以说这就是操作系统做的所有事情。
我们是否应该退出这个循环?如果需要退出,那会是什么时候呢?
-
在大多数情况下,我们不会退出这个调度循环。因为操作系统需要持续地管理和调度进程或线程以确保系统资源得到有效利用。
-
然而,在某些特定情况下可能会退出此循环。例如,在系统关机或重启时,调度器可能会停止其工作并退出此循环。另外,在某些严重错误发生时(如硬件故障、严重的内核错误等),操作系统可能也会停止运行并结束此循环。
-
请注意上述描述是在理想化和简化了一些细节后的情况,在实际操作中OS做得远不止于此,并且有许多复杂性存在。
2. Run a thread/process
首先考虑Dispatch Loop中的第一个部分:RunThread()
如何运行一个线程?
- 将其状态(寄存器,程序计数器(PC),堆栈指针)加载到CPU中。
- 默认采用的是user线程:kernel线程=1:1的模型:这也就意味着一个用户线程有用户栈和对应的内核栈,内核栈和用户栈是一一对应的。但是并不绝对,这取决于我们采用的线程模型是什么。
- 加载环境(例如虚拟内存空间等),这个可能涉及到从一个进程切换到另一个进程。
- 跳转到程序计数器(PC),意味着将控制权交给了新选定的线程。此时,CPU将开始执行该新线程的代码。
调度程序如何重新获得控制权?
- 内部事件(Internal Events):线程自愿返回控制权,这是可以预见的情况。
- 外部事件(External Events):线程被抢占,如中断抢占,这可能是不可预见的情况。
2.1 Internal Events
阻塞在I/O上:请求I/O的行为隐含地放弃了CPU。
- “阻塞在I/O上”是指当一个线程需要等待某个I/O操作(如读取文件或接收网络数据)完成时,它会自动将控制权交还给调度器。这样做是因为I/O操作通常比CPU指令执行要慢得多,如果一个线程只是坐着不动地等待I/O完成,那么它就会浪费宝贵的CPU时间。
- 一次I/O操作的时间一般可以执行100万条指令。
等待其他线程的“信号”:线程请求等待其他的进程或线程,因此可以放弃CPU。
- “等待其他线程的’信号’“是指一种常见的并发编程模式,其中一个线程需要等待另一个线程完成某些工作。例如,在生产者/消费者模型中,消费者可能需要等待生产者生成新数据。在这种情况下,消费者可以选择主动放弃其对CPU的控制权,并让出给其他可能有工作要做的线程。
线程执行yield():线程主动放弃CPU。
- “执行yield()”则是一种显式地让出CPU控制权给调度器的方法。程序员可以在他们知道现在是一个好时机让其他任务运行时使用这个方法。
2.2 Stack for Yielding Thread
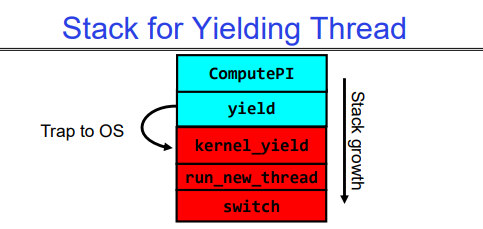
如何运行一个新线程? 我们可以通过以下函数来运行一个新线程:
run_new_thread() {
newThread = PickNewThread();
switch(curThread, newThread); // 下面重点说一下这个switch
ThreadHouseKeeping(); /* Do any cleanup */
}
在这个函数中,PickNewThread()是选择新的线程来运行,switch(curThread, newThread)负责切换当前正在运行的线程到新选定的线程,ThreadHouseKeeping()则用于执行任何必要的清理工作。
调度器如何切换到一个新线程?
- 保存下一个线程可能会修改的内容:程序计数器(PC),寄存器,堆栈指针
- 维持每个线程之间的隔离
当调度器准备切换到一个新的线程时,它首先需要保存当前正在运行的线程可能会被下一个线程修改或覆盖的所有信息。这包括程序计数器(即下一条要执行指令的地址),寄存器(存储了CPU需要进行计算和操作所需数据)以及堆栈指针(用于跟踪程序中函数调用和变量分配)。
2.2.1 User stack : kernel stack=1 : 1
此外,在多任务环境中,每个进程或者线程都应该相互隔离。也就是说,在默认情况下,一个进程不能访问另一进程的内存空间。这样可以防止错误或恶意代码影响其他任务,并有助于保护用户数据不被未经授权访问。
当一个线程调用了yield()函数进入内核态时,它的栈也会随之改变,从用户栈(蓝色)切换到内核态(红色),每个线程在内核中都会有一个属于自己的专门的内核栈。
- 在Linux操作系统中,每个线程在用户态和内核态之间切换时,都会使用各自的内核栈。这是因为在Linux中,无论是进程还是线程,在内核态中都被视为独立的任务,每个任务都有自己的
task_struct结构体来保存其状态信息,其中就包括了内核栈的信息¹。 - 当一个线程从用户态切换到内核态时(例如通过系统调用),它会切换到其自己的内核栈。如果这个切换是由于中断引起的,那么会使用对应CPU的中断栈²。
- 需要注意的是,这些栈都是在内核空间中分配的,因此它们对用户程序是不可见的。这样做主要是为了保护内核态的执行环境,防止用户态程序直接访问和修改内核态的数据¹²。
- 总的来说,每个线程在放弃CPU并切换到内核态时,都会有一个专门的栈用于保存其在内核态中的执行状态(TCB)。这样可以确保当线程再次被调度运行时,能够正确地恢复其内核态的执行环境,并继续从上次中断的地方开始执行¹²。
因此可以理解为内核栈是用来做TCB信息的保存与切换,涉及到线程/进程的切换之类的操作,或一些别的必要的操作的。
(1) 通俗易懂的了解——Linux线程模型和线程切换 - 知乎. https://zhuanlan.zhihu.com/p/138827137. (2) 操作系统进程(线程)切换内核栈存放哪些内容? - 知乎. https://www.zhihu.com/question/520012483. (3) 浅谈Linux 中的进程栈、线程栈、内核栈、中断栈 - 知乎. https://zhuanlan.zhihu.com/p/188577062.
2.3 What Do the Stacks Look Like?
举一个例子说明线程/进程之间是如何进行切换的,重点关注上面提到的在内核栈中执行的switch()调用,此外我们假设当前系统中只有一个CPU core:
假设我们有如下的两个函数:
proc A() {
B();
}
proc B() {
while(TRUE) {
yield();
}
}
假设我们有两个线程,分别是S与T,他们执行完全一致的代码段:
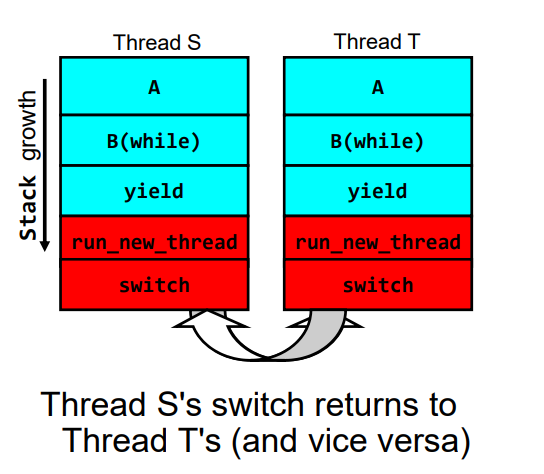
当调用switch()后,就会切换到另一个线程的栈顶,究其原因,我们来看一下switch()的伪代码:
2.3.1 Saving/Restoring state (often called “Context Switch)
Switch(tCur,tNew) {
/* Unload old thread */
TCB[tCur].regs.r7 = CPU.r7;
…
TCB[tCur].regs.r0 = CPU.r0;
TCB[tCur].regs.sp = CPU.sp;
TCB[tCur].regs.retpc = CPU.retpc; /*return addr*/
/* Load and execute new thread */
CPU.r7 = TCB[tNew].regs.r7;
…
CPU.r0 = TCB[tNew].regs.r0;
CPU.sp = TCB[tNew].regs.sp;
CPU.retpc = TCB[tNew].regs.retpc;
return; /* Return to CPU.retpc */
}
由源代码不难看出,当Switch()函数执行完后,不是返回到原地,而是返回到CPU.retpc指向的位置,由于我们已经加载了新的进程/线程的PCB,因此会返回到下一个进程中待执行的指令,我们假设此时是由S切换到了T;
T开始执行,执行yield(),切换到内核堆栈,执行Switch(),Switch完成线程切换,这时就会从T切换到S,而S此时就可以完成run_new_thread(),之后就是S线程的栈函数一路弹出,之后再次进入yield()函数,重复上面的逻辑。
因此表现出来就是S与T线程之间的反复切换。
2.4 Switch Details (continued)
线程控制块(TCB)和堆栈(用户态/内核态)包含了线程完整的可重启状态!
- 可以将其放在任何队列中,以便后面重新启动!
如果在实现切换时犯了错误会怎样?
- 假设你忘记保存/恢复寄存器32
- 根据上下文切换发生的时间和新线程是否使用寄存器32,可能会出现间歇性故障
- 系统会在没有警告的情况下给出错误的结果
你能设计一个详尽无遗的测试来测试switch()函数的代码吗?
- 不行!组合和交错太多
谨慎地讲述一个故事:
- 为了提高速度,Topaz内核在switch()中省略了一条指令
- 这是经过精心记录的!只有当内核大小<1MB时才能正常工作
- 发生了什么?
- 时间过去了,人们忘记了。
- 后来,他们向内核添加了功能(没有人移除功能!)
- 开始出现非常奇怪的行为
- 故事寓意:追求设计简单性
2.5 Aren’t we still switching contexts?(用户线程与内核线程的对应关系)
我们不是仍在进行上下文切换吗?
- 是的,但这比切换进程要便宜得多。因为切换进程需要更改地址空间,而这会消耗更多的时间和资源。
来自Linux的一些数据:
-
上下文切换频率:10-100毫秒
-
切换进程:3-4微秒
-
切换线程:100纳秒
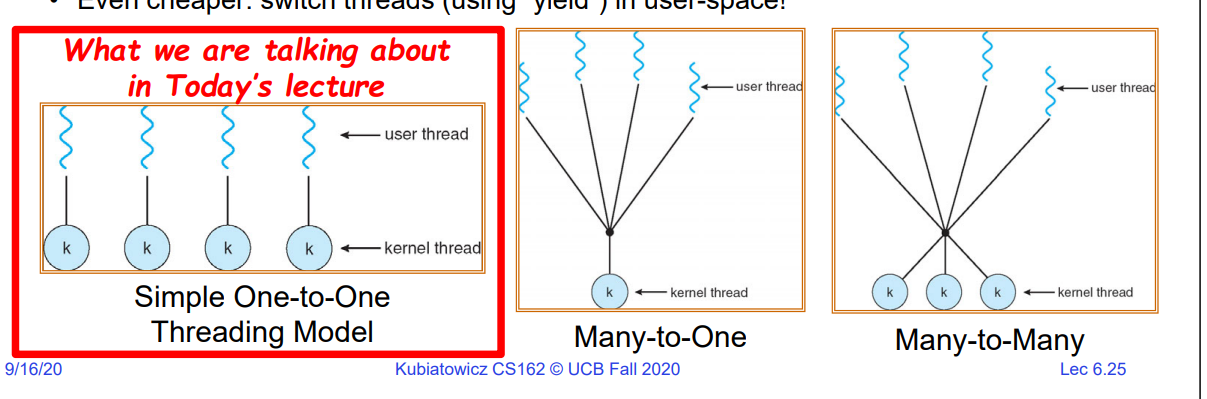
甚至更便宜:在用户空间使用“yield”函数强制线程放弃CPU控制权,以便其他线程可以运行!我们在用户态调用用户级别的yield()函数,用户代码库知道如何进行做同栈切换,他在线程切换之间保存并恢复寄存器的状态,但是不需要进入内核态。
1对1的模型优点是每个用户线程都有一个对应的内核级线程,当一个线程因为I/O操作被放入wait队列时,这意味着它的内核线程被放入了等待队列,但是别的线程依然可以继续运行。
多对一线程虽然在拥有同一个内核栈的线程之间进行切换的效率更高,不必进入内核态,但是一旦有一个线程因为I/O操作阻塞,对应的内核级线程被放入wait队列,那么该内核级线程对应的所有用户级线程都不能被运行。
因此折中一下,就出现了多对多线程模型:少量的内核级线程对应了更多的用户级线程。今天我们只会讨论
2.6 Processes vs. Threads
1. one core
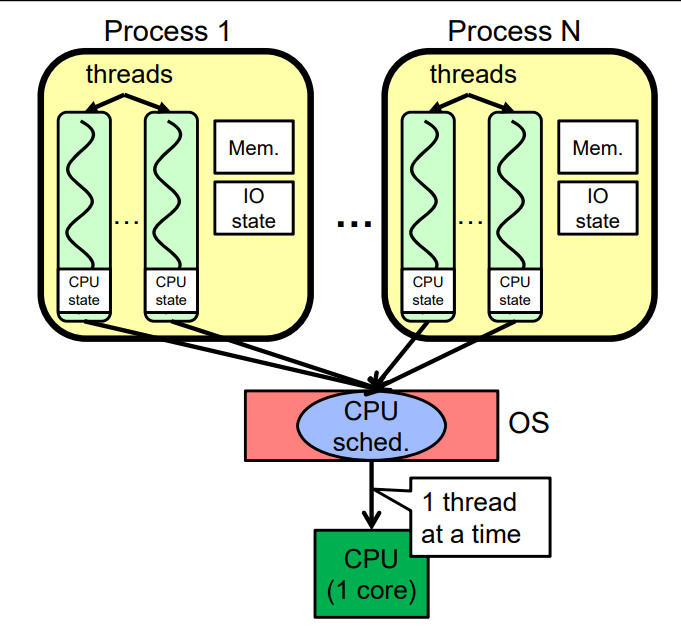
切换开销:同一进程内进行线程切换开销低,不同的就高。
保护:同一进程内的线程保护程度较低,不同的就高。
共享开销:同一进程内的共享开销低,不同的高
并行性:单核没有并行性。
2. Multi-core
上层与上图相似,只不过最底层的CPU core从1个变成了多个。
切换开销:同一进程内进行线程切换开销低,不同的就高。
保护:同一进程内的线程保护程度较低,不同的就高。
共享开销:同一进程内的共享开销低;不同的进程,且目标进程目前都在CPU core上运行,那么共享的开销是中等;不同的进程,且有一些进程没有在CPU core上运行,那么共享的开销就很高。
并行性:多个cpu cores当然具有并行性。
2.7 Simultaneous MultiThreading/Hyperthreading
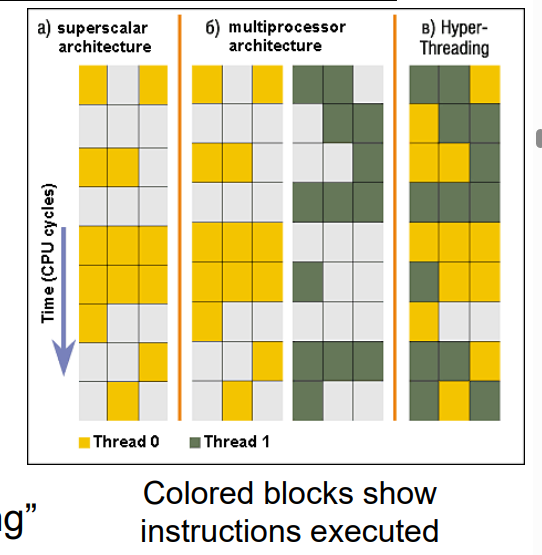
黄色与棕色意味着正在执行指令,灰色代表空闲。
硬件调度技术
- 超标量处理器(图中a部分)可以同时执行多个独立的指令。
- 超线程(图中c部分)复制寄存器状态以创建第二个“线程”,允许运行更多的指令。
可以调度每个线程,就好像它是单独的CPU
- 但是,子线性加速!尽管使用了超线程技术可以增加整体效率,但其效果往往不会直接地成倍增长——即并不能达到理想中完全平行计算应有的那种效果。因此我们说它只能实现”子线性加速”。
原始技术称为“同时多线程”
- http://www.cs.washington.edu/research/smt/index.html
- SPARC, Pentium 4/Xeon(“超线程”),Power 5
超线程技术和超标量架构是两种不同的提高CPU性能的技术,实际上它们可以在同一处理器中同时使用。它们各自具有自己的优势,并解决了CPU利用率的不同方面。
超标量架构是一种在处理器中用于在一个时钟周期内执行多于一条指令的方法。这是通过同时将多个指令分派到处理器的不同部分来实现的。对于可以并行或独立执行指令的任务,超标量处理器可以大大提高性能。
另一方面,超线程(也称为同时多线程)是一种允许在单个核心上执行多个线程的技术,有效地使操作系统将一个物理核心视为两个虚拟核心。超线程的目标是增加每个CPU核心内计算资源的利用率,并更好地支持多任务处理。
就资源利用率而言,当某些线程等待I/O操作或内存访问时,超线程可以帮助保持CPU忙碌,因为其他线程可以同时执行。然而,与当有许多可立即执行的独立指令时像超标量执行那样增加原始计算吞吐量并不完全相同。
所以说,比起超标量架构,是否会因为使用了超线程技术而使得 CPU 被更充分地利用起来其实真正取决于运行在计算机上特定工作负载类型。对于有很多独立指令需要被运算处理的任务来说, 超标量设计可能会带来显著效益; 对于需要频繁等待(例如很多服务器工作负载) 的任务场景, 则最好使用超线程技术得到整体更好地利用效果。
3. External Events
3.1 What happens when thread blocks on I/O?
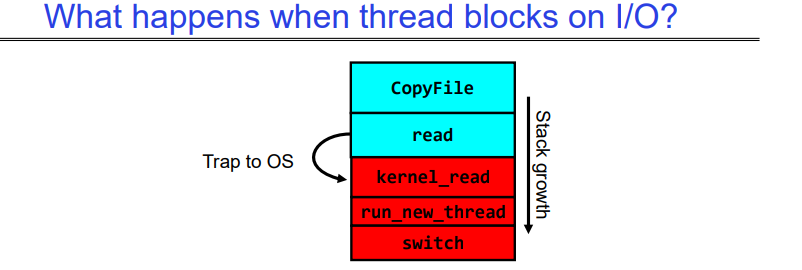
当一个线程需要从文件系统中读取一块数据时,首先由用户空间的代码发起一个系统调用。这个系统调用会被操作系统内核捕获,并开始执行相应的文件读取操作。
读取操作启动后,数据从磁盘(或其他存储设备)被加载到内存中。这个过程可能需要一些时间,因为它涉及到I/O操作,这通常比CPU和内存之间的交互要慢得多。
在等待数据加载的同时,操作系统可能会选择运行其他的线程或者进行上下文切换。这样可以更充分地利用CPU资源,而不是让它在等待I/O操作完成时闲置。
对于线程之间的通信也有类似的过程。例如,在某些情况下,一个线程可能需要等待另一个线程发送一个信号或者完成某项任务(通过join机制)。在网络编程中,也经常需要进行类似的等待——例如,在发送请求并等待服务器响应时。
可知,上述线程包含了一个用户站和一个内核栈,switch操作负责保存当前线程的执行状态,之后切换到另一个线程,返回当前线程的用户态程序。
3.2 External Events
如果线程从不进行任何I/O操作,从不waits,也从不yields控制权会发生什么?
- ComputePI程序能否抢占所有资源并永远不释放处理器?
- 如果它没有打印到控制台会怎样?
- 必须找到一种方式让调度器可以重新获得控制权!
答案:利用外部事件(External Events)
- 中断(
Interrupts):来自硬件或软件的信号,停止正在运行的代码并跳转到内核 - 计时器(
Timer):就像一个每隔一段毫秒就响起的闹钟
如果我们确保外部事件频繁地发生,就可以确保调度器运行。
在多任务操作系统中,如果一个线程从未进行任何I/O操作、等待(waits其他线程)或主动放弃CPU(例如通过yield),那么理论上这个线程可以一直占用CPU而不被打断。这可能会导致其他线程无法得到执行机会。
为了防止这种情况发生,现代操作系统通常采用抢先式多任务调度策略。在这种策略下,即使一个线程想要无限制地使用CPU也做不到。因为操作系统有一个叫做“计时器”的机制——每当计时器达到预设的时间间隔(比如几十毫秒)后, 它就会产生一个中断信号。
当中断信号产生后, CPU 就会立刻停止当前正在执行的任务, 转而去处理这个中断: 它将保存当前任务的状态, 然后跳转至内核特定的中断处理程序去执行相应操作——在此例中则是进行任务切换。
所以说只要我们确保”外部事件”(比如由计时器产生的中断)足够频繁地发生, 那么我们就能确保调度器有机会去运行并对 CPU 进行合理分配。
3.3 Interrupt Controller
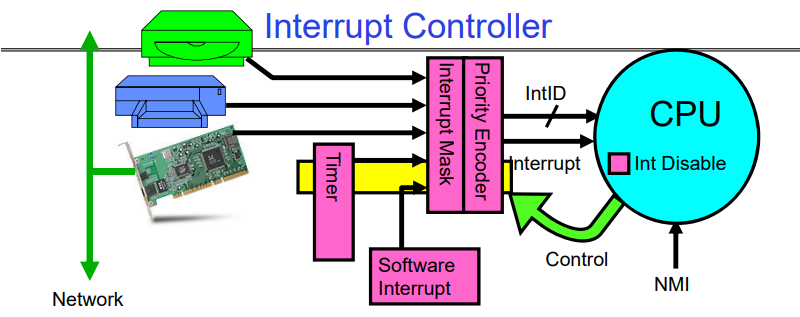
在计算机系统里,硬件设备通过向CPU发送信号来触发”硬件中断”。这些信号是通过所谓的”中断线”(Interrupt Lines)传递的。
当有多个设备同时发送了信号时,就需要有一个叫做“中断控制器”(Interrupt Controller)的硬件来决定哪个请求应该被优先处理。它会根据每个请求所带有的“ID”和其对应“优先级”来进行判断。
“掩码”是一种可以让我们手动开启或关闭某些特定类型或者特定设备产生的 中断 的工具。
对于那些我们希望在任何情况下都不被打扰的重要任务, 我们甚至可以让 CPU 直接忽略所有类型的 中断 请求。但唯一例外就是那些经过 “不可屏蔽位” (Non-Maskable Interrupt, NMI) 发起 的请求——正如其名字所表达出来那样, 这类请求无论在什么情况下都不能被忽视或者说是阻止。
另外还存在一种叫做 “软件触发式 中断” (Software Interrupt) 的机制: 它并非由硬件设备发起, 而是直接由运行在 CPU 上面代码所主动调用——例如我们可能会使用这种方式来手动触发一个系统调用操作。
3.4 Example: Network Interrupt
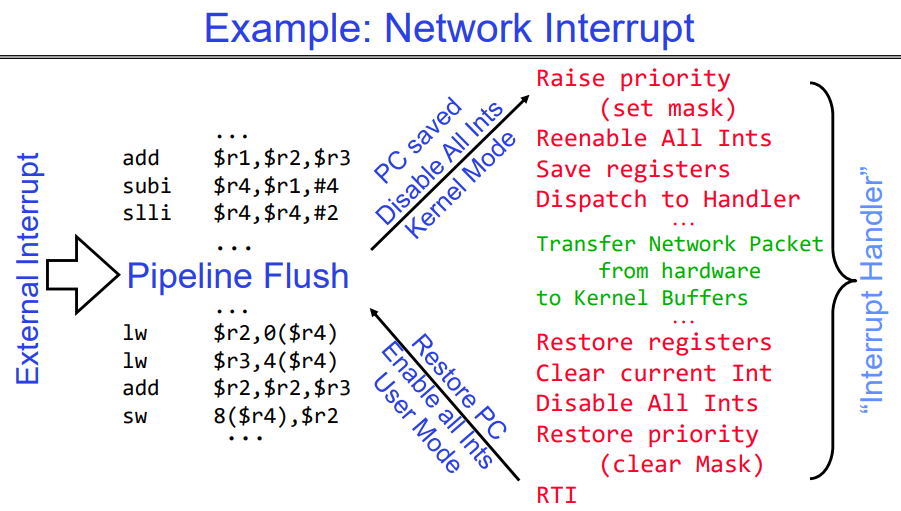
在计算机系统中,当硬件设备(如键盘、鼠标、网络卡等)需要CPU注意时,它们会通过发送一个信号来触发一个”硬件中断”。
当CPU收到这个信号后,它会立刻停止当前正在执行的任务,并保存其状态(这就是所谓的”上下文切换”),然后跳转到预先设定好的特定位置去执行对应的 “中断处理程序”(Interrupt Handler)。
这个过程并不需要我们人工干预或者说进行任何额外操作——比如说选择接下来要运行哪个任务——因为所有相关操作都已经在系统初始化或者设备驱动加载时被自动设置好了。所以我们可以说,一旦一个中断请求被触发, 那么相应的中断处理程序就会被立即执行。
3.5 Use of Timer Interrupt to Return Control
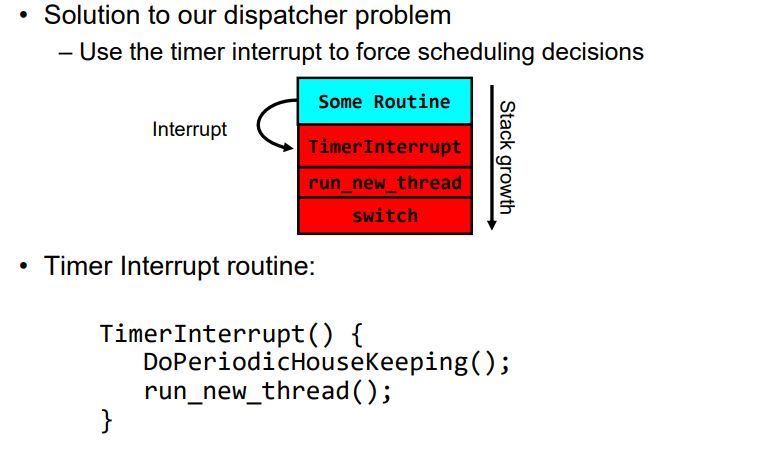
在接收到这个信号后,操作系统会执行一段名为 “TimerInterrupt()” 的特殊函数(也称为“中断服务例程”)。在这个函数里,我们可以首先完成一些必要的维护工作(如更新系统时间、检查硬件状态等),然后再根据当前所有待处理任务的状态和优先级选择下一个应该被执行的线程,并将CPU控制权交给它。
这样做有两个主要好处:首先,通过固定间隔地切换任务,我们可以确保每个线程都能得到公平地运行机会;其次,在每次切换前都重新评估并选择最合适的线程来运行也使得我们能更灵活有效地响应各种动态变化情况——比如突然有新高优先级任务加入等。
3.6 How do we initialize TCB and Stack?

初始化TCB的寄存器字段
- 让栈指针指向栈
- 程序计数器(PC)返回的地址 → 操作系统(汇编)例程ThreadRoot()
- 将两个参数寄存器(a0和a1)分别初始化为
fcnPtr和fcnArgPtr
初始化栈数据?
- 不。栈帧的重要部分在寄存器(ra)中
- 可以将栈帧看作是
ThreadRoot()主体真正开始之前的状态
在多线程编程中,每个线程都有自己独立的执行环境,包括一块私有的内存空间(即”栈”),以及一个用于记录其运行状态的 “线程控制块” (Thread Control Block, TCB)。其中,堆栈用于保存函数调用过程中产生的局部变量、返回地址等信息;而 TCB 则主要保存了一些更底层或者说是全局性质的信息——比如 CPU 寄存器值、线程优先级、状态等。
在创建一个新线程时,我们首先需要初始化其 TCB 和 堆栈。对于 TCB 来说, 我们需要设置其各个字段到合适初始值——例如让 “堆栈指针” (Stack Pointer) 指向新分配给这个线程使用 的内存区域顶部;将 “程序计数器” (Program Counter) 设置为 ThreadRoot() 函数入口点;并且还可能需要设置其他各种参数。
对于堆栈来说,在函数调用过程中会动态地被修改和更新, 所以在初始化时我们通常不会去预设任何特定数据。相反,在大多数情况下,我们只需确保它有足够空间可以容纳接下来可能产生的数据即可。
这里提到“重要部分”的“ra”应该是指“返回地址”(Return Address),这是一个非常关键的概念:当一个函数被调用时,CPU 需要记住当前正在执行代码 的位置 —— 也就是 下一条将被执行的指令地址——这样当函数执行完毕后,CPU 才能知道应该跳回到哪里去继续执行。在大多数系统中,这个 “返回地址” 通常会被保存在一个特殊的寄存器或者堆栈里。
3.7 How does Thread get started?
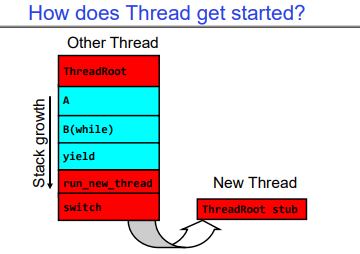
在操作系统中,创建一个新线程需要进行一系列步骤。首先,我们需要设置一个新的线程控制块(TCB)或内核线程,让它指向一个新分配的用户栈空间和ThreadRoot代码。ThreadRoot是每个新线程默认会执行的函数。
接下来,我们需要将要执行函数及其参数的指针放入寄存器中。这里要注意,如何设置这些值以及使用哪些寄存器会取决于具体使用的硬件架构和调用约定。例如,在RISC-V和x86两种架构中就可能有不同。
一旦所有这些都设置好后, 我们就可以把这个新创建 的 TCB 加入到系统待运行队列里去了。
最终,run_new_thread()将选择这个TCB并返回到ThreadRoot()的开始
- 这实际上启动了新的线程
在多线程编程中,一个新的线程从创建到最终运行,通常需要经过以下几个步骤:首先,我们需要分配和初始化一块新的内存空间(即”堆栈”)和一个 “线程控制块” (TCB);然后将这个新创建的 TCB 加入到系统的调度队列中。
当操作系统决定要运行一个新线程时(例如在处理完一个定时器中断后),它会通过调度算法选择下一个应该被执行的 TCB (比如说 run_new_thread() 函数就可能是完成这一任务)。然后操作系统会设置好所有必要环境(比如寄存器值、程序计数器等),并将CPU控制权交给这个新选出来 的 TCB 所代表 的 线程。
在这个过程中,程序计数器被设置为 ThreadRoot() 函数入口点地址。因此当 CPU 开始执行新代码时, 它实际上是在执行 ThreadRoot() 函数——也就是说, 新线程从 ThreadRoot() 开始运行。ThreadRoot() 通常会包含或者调用实际想要在线程里执行 的 用户函数。
3.8 What does ThreadRoot() look like?
ThreadRoot()是线程例程的根:
ThreadRoot(fcnPTR,fcnArgPtr) {
DoStartupHousekeeping();
UserModeSwitch(); /* enter user mode */
Call fcnPtr(fcnArgPtr);
ThreadFinish();
}
启动时的维护工作
- 包括记录线程开始时间等事项
- 其他统计信息
栈将随着线程执行而增长和缩小
线程最后返回到ThreadRoot(),该函数会调用ThreadFinish()
- ThreadFinish()唤醒正在睡眠的线程,之后可以让别的ready queue的线程被调度运行。
ThreadRoot()函数通常被设计为每个新创建的线程默认会执行的第一个函数。它通常需要完成一些初始化和启动前准备工作,然后再转去运行实际想要在线程里执行的用户函数。
在这个例子中,ThreadRoot()首先完成了一些”启动时维护”工作——例如记录下这个新线程开始运行的时间以及可能还有其他一些统计信息等。
接下来,它切换到了”用户模式”。在操作系统中,通常会有两种不同级别的运行模式:内核模式和用户模式。内核模式具有完全访问硬件资源和所有内存区域的权限,而用户模式则只能访问限定范围内的资源和内存。新创建的线程通常会在用户模式下运行。
完成这些准备工作后,ThreadRoot()就可以调用fcnPtr函数了——这就是我们实际想要在线程里去完成的工作。
当fcnPtr函数执行完毕并返回后,控制权又回到了ThreadRoot().此时它会调用另一个特殊函数:ThreadFinish(),来完成一些清理工作并标记这个线程已经结束.
在多任务环境中,当一个任务(或者说“线程”)结束时,可能需要唤醒其他一些因为等待它而被挂起(或者说“睡眠”)的任务。所以在这里我们看到:ThreadFinish()还负责唤醒那些正在睡眠的线程。
4. Concurrent Examples-ATM Bank Server
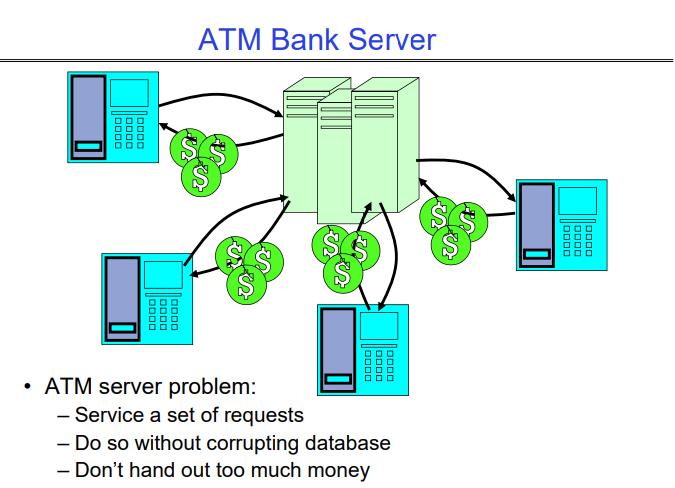
4.1 Simple Solution
BankServer() {
while (TRUE) {
ReceiveRequest(&op, &acctId, &amount);
ProcessRequest(op, acctId, amount);
}
}
ProcessRequest(op, acctId, amount) {
if (op == deposit) Deposit(acctId, amount);
else if …
}
Deposit(acctId, amount) {
acct = GetAccount(acctId); /* may use disk I/O */
acct->balance += amount;
StoreAccount(acct); /* Involves disk I/O */
}
我们如何加速这个过程?
- 同时处理多个请求
- 事件驱动(计算和I/O重叠)
- 多线程(多进程,或者计算和I/O重叠)
在上述的银行服务器例子中,我们可以看到每次只能处理一个ATM的请求。这意味着如果有很多并发的ATM操作,那么其他所有人都需要等待当前操作完成后才能进行他们的操作。
为了提高系统性能,我们可以引入并发编程技术。例如:我们可以让服务器同时处理多个客户端发送过来 的 请求——也就是说,在一个客户端的操作还在进行时(比如正在等待硬盘IO),服务器就已经开始去处理下一个客户端 的 请求了。
还有一种方法通常被称为 “事件驱动” 或者 “异步IO”:即当某个IO操作需要等待时(比如读写硬盘),不是让整个程序都停下来等待它完成,而是将其挂起,并立即开始去做其他事情。然后当那个IO操作真正完成后再通过某种机制(比如回调函数或者事件)通知程序继续执行它。
另一种提高性能的方法是 使用 “多线程” 技术:即 在 同一时间内让多个线程并行地运行。每个线程都有自己独立 的执行环境和堆栈空间,所以它们可以分别执行不同任务,并且相互之间几乎没有影响。这样既可以利用多核CPU的优势提高总体计算性能,也可以通过让不同线程处理不同任务来提高系统的响应速度。
4.2 Event Driven Version of ATM server(编程难度高)
假设我们只有一个CPU
- 仍然希望将I/O与计算重叠
- 如果没有线程,我们将不得不以事件驱动的方式重写代码
BankServer() {
while(TRUE) {
event = WaitForNextEvent();
if (event == ATMRequest)
StartOnRequest();
else if (event == AcctAvail)
ContinueRequest();
else if (event == AcctStored)
FinishRequest();
}
}
在这个事件驱动版本的ATM服务器示例中,主要思想是通过等待和响应不同类型的事件来实现服务。例如:当收到一个新的ATM请求时,它就开始处理这个新请求;当得知某个账户已经可用时,它就可以继续之前暂停的请求;最后当账户信息被成功存储后,它就可以标记当前操作已经完成,并准备接收下一个操作。
这种模式虽然可以有效地提高单核CPU使用效率(因为在等待IO时还能去做其他事情),但也有一些潜在问题:比如说如果在编写程序时忘记了某些可能导致阻塞的操作, 那么整个程序可能会卡住而无法正常运行。
另外,在复杂系统中可能需要处理很多不同类型的事件,并且每种类型的事件可能都需要对应不同的处理函数。如果每个函数都只能做一小部分工作(以避免长时间阻塞),那么整个程序可能需要被切割成很多小片段——这无疑会大大增加编程难度和出错风险。
尽管如此,由于其优秀的响应性和资源利用率,这种技术仍然广泛应用于许多领域——尤其是需要实时交互或者对延迟敏感的场合。比如说图形界面编程、网络编程、游戏开发等等。
4.3 Can Threads Make This Easier?
使用多线程可以让编码变得更简单。你可以让每个请求都在自己的线程中运行,并且允许它们根据需要阻塞。这样就不需要将你的代码分割成非阻塞片段或者处理复杂的事件循环了。
然而,多线程也带来了新的问题:当多个线程同时访问和修改同一份数据(也就是所谓的”共享状态”)时,可能会导致数据被错误地修改或者破坏。在上述例子中,两个并发执行的存款操作可能会导致账户余额计算错误。
为了避免这种问题,我们通常需要引入某种形式的”同步”或者”互斥”机制来确保每次只有一个线程能够访问和修改那些共享数据。例如:在上述例子中我们可能需要使用一个锁来保护对账户余额的修改操作——即在开始修改前先尝试获取锁,并且只有成功获取到锁后才真正去执行修改操作;然后在完成修改后再释放那把锁。这样就可以确保即使有很多并发执行的存款操作,但任何时候都只有一个操作能够真正去改变账户余额。
所以我们需要让某些操作或某些操作的组合变成Atomic Operation。
4.4 Atomic Operations
对于大部分计算机系统来说,单个内存单元的读取和写入操作都是原子的。也就是说如果一个线程正在写入某个内存位置,那么其他所有尝试读取或者写入那个位置的线程都必须等待它完成才能继续。
这只意味着Load和Store这两个汇编指令是原子的(每次针对一个内存单元)。
然而,并非所有类型的操作都是原子性。比如说对于双精度浮点数或者大数组等大型数据结构的读写就可能不是原子性。这意味着如果有两个线程同时尝试去写入同一个双精度浮点数或者复制同一个数组,那么结果可能会出现混乱——因为两次操作可能会交错进行,导致最后得到了一些既非完全由第一次操作产生、也非完全由第二次操作产生、而是由两者混合产生的”脏数据”。
因此,在编写并发程序时,我们需要非常清楚地了解哪些操作是原子的,哪些不是。对于那些非原子操作,我们需要采取额外的措施来确保数据的完整性和正确性。例如,我们可以使用锁或者其他同步机制来保证在任何时候都只有一个线程能够访问和修改那些数据。
例如,在多线程环境中处理双精度浮点数或复制大型数组时,可能需要引入锁。当一个线程开始这样的操作时,它会首先获取锁,然后执行操作,最后释放锁。在这个过程中,任何其他试图执行相同操作的线程都必须等待直到第一个线程完成并释放了锁。
这种方法可以防止数据冲突和不一致性问题,并确保你的程序在并发环境下能够正确地运行。然而,请注意使用锁也有其代价:它会增加程序复杂性,并可能导致性能下降(因为现在一次只能有一个线程执行某些操作)。因此,在设计并发程序时,应该尽量减少共享数据和必须进行同步的情况。
总结起来说,在理解并编写并发程序时,知道哪些是原子操作是至关重要的。同时还需要理解如何通过使用同步机制(如互斥量、信号量等)来处理非原子操作带来的挑战。
下面就是关于线程之间并发的案例分析。
5. Conclusion
通过复用CPU时间来实现并发:
- 卸载当前线程(PC,寄存器)
- 加载新线程(PC,寄存器)
- 这样的上下文切换可能是自愿的(yield(),I/O)或者非自愿的(中断-interrupts)
TCB + 堆栈(stack)保存线程的完整状态以便重新启动
原子操作(Atomic Operation):一个总是运行到完成或者根本不运行的操作
同步(Synchronization):使用原子操作确保线程之间的协作
互斥(Mutual Exclusion):确保一次只有一个线程执行特定任务
- 一个线程在执行其任务时排除其他线程
关键区段(Critical Section):一次只有一个线程会进入这部分代码并执行。
锁(Locks):用于在关键区段上强制实施互斥以构造原子操作的同步机制
信号量(Semaphores):用于强制实施资源约束的同步机制
以上都是处理并发编程中常见问题和概念。理解这些基础知识对于设计和实现正确、高效且可靠 的 并发程序至关重要。同时,请记住并发编程通常比单线程编程更复杂,并且需要更细致地考虑各种可能出现问题的场景。