Abstractions 2: Files and I/O A quick programmer’s viewpoint
1. Intro && Recall
1.1 locks and semaphores
除了上节课讨论的lock之外,lock.Acquire(),lock.Release(),还有一种称为semaphores(信号量)的工具可以用来进行线程间协作:
Semaphores(信号量)是一种泛化的锁:
- 它们首次由Dijkstra在20世纪60年代末提出。
Semaphores是原始UNIX(以及Pintos)操作系统中主要使用的同步原语。
定义:信号量具有非负整数值,并支持以下两种操作:
- P() 或 down():一种原子操作,等待信号量变为正数,然后将其减1。
- V() 或 up():一种原子操作,将信号量加1,如果有等待的P()操作,则唤醒它。
P() 代表荷兰语中的“proberen”(测试),V() 代表荷兰语中的“verhogen”(递增)。
信号量用于解决多线程或多进程环境中的互斥访问和同步问题。例如,信号量可用于保护临界区资源,确保一次只有一个线程或进程可以访问它,从而避免数据竞争和并发问题。信号量还可用于实现生产者/消费者问题等同步场景,其中线程或进程需要等待某个条件成立才能继续执行。
通过给信号量不同的初始值,信号量可以有多种用途,适用于不同场景。
1.2 Goals for Today:The File Abstraction
在本次讨论中,我们将完成进程管理话题的讨论,并涵盖以下主题:
- 高级文件I/O:流(Streams): 高级文件I/O通过流(如C语言中的FILE结构体类型)进行操作。流提供了对文件I/O的抽象,使程序员能够以简单、通用、易于理解的方式执行文件操作,例如打开、关闭、读取、写入文件等。流会处理缓冲区,使得文件I/O操作更高效。
- 低级文件I/O:文件描述符(File Descriptors): 与高级文件I/O不同,低级文件I/O直接操作文件描述符。文件描述符是整数,用于唯一标识打开的文件。在Unix/Linux系统中,通过底层函数(如open(), read(), write(), close()等)处理文件操作。这些函数提供了更多控制选项,但相对较复杂。
- 高级文件I/O的原理及作用: 高级文件I/O(流)在底层实现时使用低级文件I/O(文件描述符)。通过流抽象,程序员可以更方便地实现文件操作,而无需关心更多控制细节。
- 文件描述符的进程状态: 每个进程都有一个文件描述符表,用于保存当前打开的文件及其状态信息。在进程创建(如fork())或执行新程序(如exec())时,文件描述符表也会受到影响。例如,在fork()之后,子进程会复制父进程的文件描述符表;在调用exec()时,通常指定某些文件描述符在执行新程序后仍然保持打开状态。
- 操作系统抽象的常见陷阱: 尽管操作系统抽象(如线程、进程和文件I/O)简化了程序员的任务,但在使用它们时也可能出现问题。例如,在多线程程序中可能会出现数据竞争、死锁等问题;在使用文件I/O时可能会遇到资源泄漏、性能问题等。因此,在实际开发中,程序员需要加以关注,确保正确地使用操作系统抽象并避免潜在问题。
1.3 What’s pthread?
pthread库:POSIX线程库
POSIX:便携式操作系统接口(Portable Operating System Interface),主要针对类Unix系统。
- POSIX主要为应用程序开发人员提供接口。
- 它定义了“Unix”这个术语,源自AT&T Unix。
- POSIX的创建旨在为许多基于Unix的操作系统带来秩序,使得应用程序可以进行跨平台移植。
- 部分POSIX功能在非Unix操作系统上也有实现,如Windows。
- POSIX要求提供标准系统调用接口。
pthread库是POSIX线程库,它提供了一套线程创建、同步和管理等方面的API。这套API遵循POSIX线程规范,因此应用程序可以在满足规范的不同操作系统中使用这些函数。
pthread库提供了线程创建、互斥锁、条件变量、信号量等功能,使得程序员可以轻松地编写多线程程序,实现并发和资源控制。在非Unix系统上使用类似功能,也可以找到相应的线程库,如Windows上的Win32线程库。
使用POSIX线程库编写的多线程程序对于许多基于Unix的操作系统具有一定的可移植性,而且兼容性较好。
1.4 Unix/POSIX Idea: Everything is a “File”
统一接口包括:
- 磁盘上的文件
- 设备(终端、打印机等)
- 磁盘上的普通文件
- 网络(套接字)
- 本地进程间通信(管道、套接字)
这些接口基于系统调用open(), read(), write()和close()。对于某些不太适合的自定义配置,还可以使用ioctl(),当我们开发设备驱动程序与内核的接口时,如果发现不能用统一接口来编写,那么就可以使用iotcl()。
需要注意的是,“一切皆文件”的这个理念在最初提出时非常激进。
Dennis Ritchie和Ken Thompson在他们的重要论文《UNIX时间共享系统》(The UNIX Time-Sharing System,1974年)中描述了这个理念。如果您对这篇论文感兴趣,可以在资源页面中查找并阅读。
在UNIX和类UNIX系统中,将各种资源都视为文件是一个核心概念。通过使用一致的接口,在许多操作系统级别的任务中都可以简化编程,提高可移植性。无论是文件、设备还是进程间通信,都可以通过类似的方式进行操作,使得应用程序在处理这些资源时的逻辑更加简明清晰。
1.5 The File System Abstraction
文件系统抽象包括以下几个方面:
文件:文件系统中的一个命名数据集合。
- 在POSIX中,文件数据是字节序列,可以包含文本、二进制、序列化对象等。
- 文件元数据是关于文件的信息,例如大小、修改时间、所有者、安全信息和访问控制。
目录:包含文件和目录的“文件夹”。
- 目录采用层次结构(或称为图结构)命名,通过目录/图的路径来唯一标识文件或目录。
- 严格来说是层次(树状)结构,但是当加入links后,他会变得更像一个图,后面会详述。
- 例如:
/home/ff/cs162/public_html/fa14/index.html
链接和卷(稍后讨论)。
1.6 Connecting Processes, File Systems, and Users
每个进程都有一个当前工作目录(CWD),可以通过系统调用设置当前工作目录: int chdir(const char *path); // 改变CWD
绝对路径会忽略CWD。例如:/home/oski/cs162
相对路径是相对于CWD的。例如:
index.html或./index.html:表示当前工作目录下的index.html文件。../index.html:表示当前工作目录的父目录中的index.html文件。~/index.html或~cs162/index.html:表示主目录(home目录)下的index.html文件。~在这里代表的是当前用户的主目录的意思。如~代表了/home/hyl。
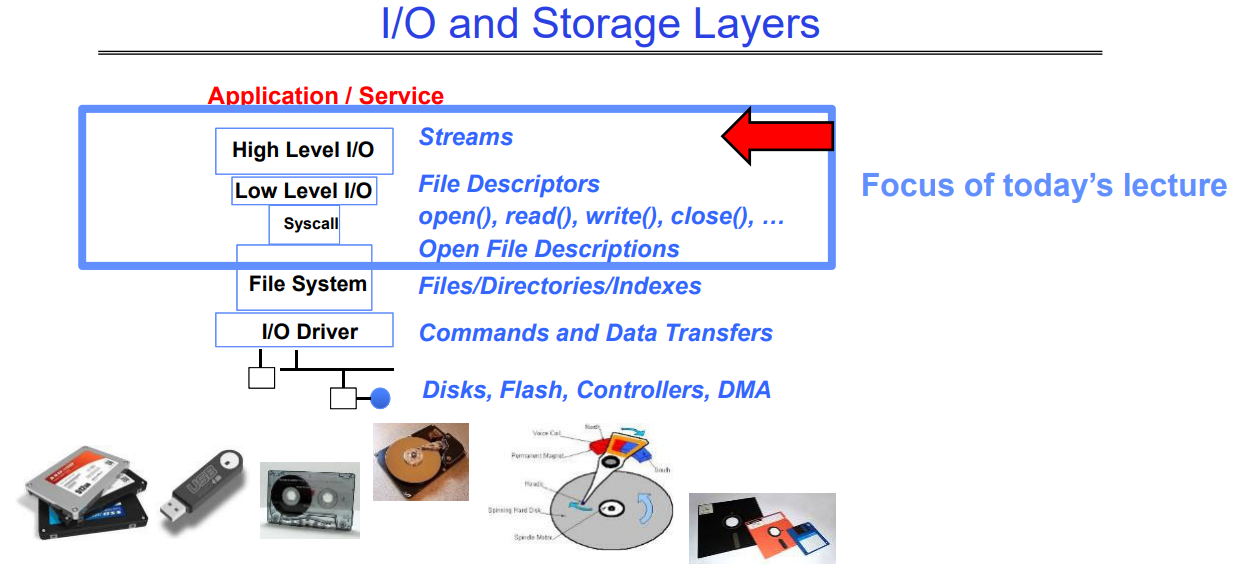
1.7 I/O and Storage Layers
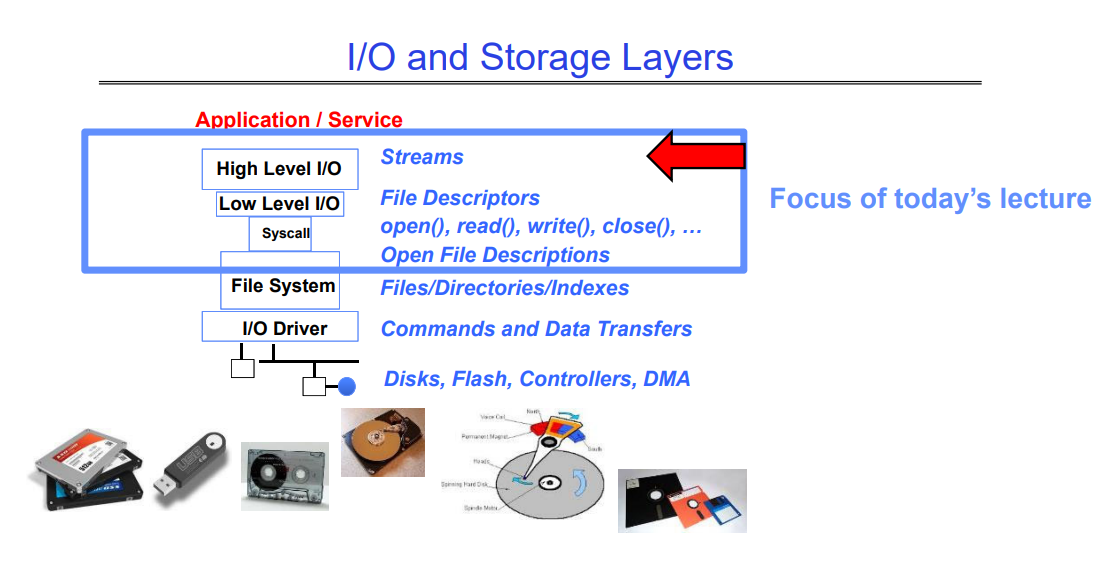
2. High-Level File I/O: Streams
2.1 C High-Level File API – Streams
C标准库中的文件操作主要通过“流”(streams)进行,它是一种无格式的字节序列(文本或二进制数据),在流中有一个指示位置的指针(就是指向FILE数据结构的指针FILE*)。
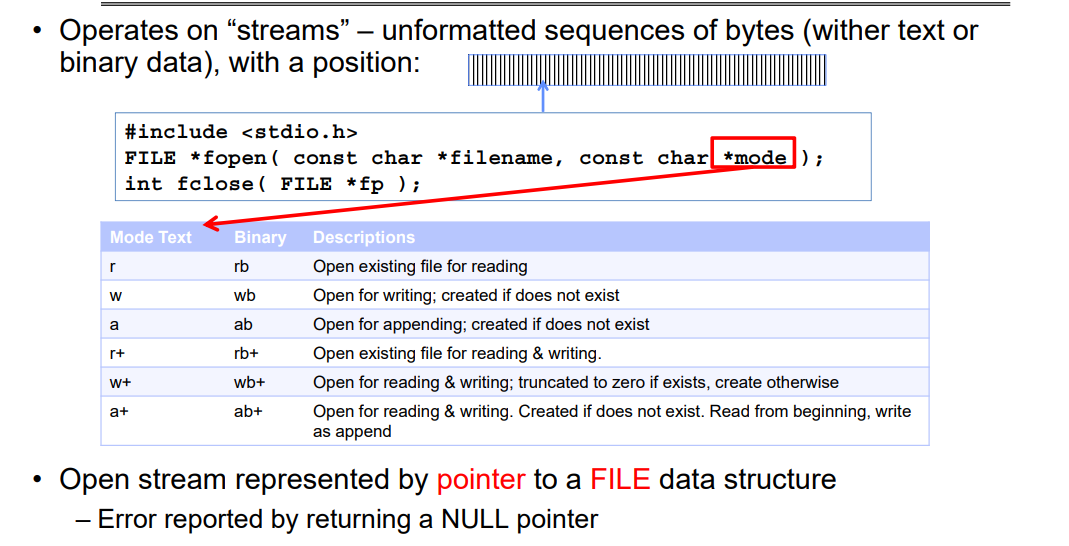
在C语言中,通过指向`FILE`数据结构的指针来表示打开的流。当文件操作发生错误时,通常会返回一个空指针(NULL)来报告错误。 通过使用FILE指针,可以在C语言中方便地表示和操纵文件流,完成文件的读取、写入、追加和其他操作。同时,这种设计有助于兼容不同文件系统和硬件实现,使得应用程序更加通用。
2.2 C API Standard Streams – stdio.h
当程序执行时,会隐式地打开三个预定义的流:
FILE *stdin:通常作为输入来源,可以被重定向。FILE *stdout:通常作为输出来源,也可以重定向。FILE *stderr:用于诊断和错误信息输出。
STDIN(标准输入)和STDOUT(标准输出)在Unix系统中实现了程序之间的组合。
所有这些预定义流都可以被重定向。
例如,在Unix终端中,可以使用以下命令重定向cat和grep程序之间的输入和输出,这是一种进程间通信的方式:
cat hello.txt | grep "World!"
在这个命令中,cat 命令从 hello.txt 文件中读取内容并将其输出到 STDOUT(标准输出),接着通过管道符号(| 这个符号)将 cat 的输出重定向到 grep 命令的 STDIN(标准输入)。最后,grep 命令在接收到的输入内容中搜索包含 “World!” 的行并显示在屏幕上。
通过这种简单的重定向功能,Unix 系统允许我们将多个程序组合在一起,实现更加复杂的任务。
2.3 C High-Level File API
C标准库提供了一组用以处理文件输入输出的功能,例如针对字符和块的操作,以及格式化操作。
面向字符的操作:
int fputc(int c, FILE *fp);:将字符c写入文件流fp,成功时返回字符c,失败时返回EOF。int fputs(const char *s, FILE *fp);:将字符串s写入文件流fp,成功时返回非负值,失败时返回EOF。int fgetc(FILE *fp);:从文件流fp中读取一个字符并返回。char *fgets(char *buf, int n, FILE *fp);:从文件流fp中读取一行(最多n-1个字符,含终止字符’\0’),并将其存储在buf中。
面向块的操作:
-
size_t fread(void *ptr, size_t size_of_elements, size_t number_of_elements, FILE *a_file);:从文件中读取number_of_elements个大小为size_of_elements字节的元素,并将其存储在ptr指向的内存区域。返回读取到的字符个数。 -
size_t fwrite(const void *ptr, size_t size_of_elements, size_t number_of_elements, FILE *a_file);:将ptr指向的内存中number_of_elements个大小为size_of_elements字节的元素写入文件。
格式化操作:
int fprintf(FILE *restrict stream, const char *restrict format, ...);:将格式化字符串输出到文件流stream。int fscanf(FILE *restrict stream, const char *restrict format, ... );:从文件流stream中读取数据,并根据指定格式解析存储到指定的变量中。
这些函数使得开发者可以方便地在C程序中读写文件,实现字符串、二进制数据等多种数据类型的输入输出。同时,这些函数也为不同硬件和文件系统提供了一致的接口。
2.3.1 C Streams: Char-by-Char I/O
int main(void) {
FILE* input = fopen(“input.txt”, “r”);
FILE* output = fopen(“output.txt”, “w”);
// 为什么用int类型保存获取到的字符
int c;
c = fgetc(input);
while (c != EOF) {
fputc(output, c);
c = fgetc(input);
}
fclose(input);
fclose(output);
}
在这段代码中,int 类型用于保存从 input 文件中获取到的字符,因为 fgetc 函数返回一个 int 类型的值。fgetc 函数从指定的流中读取下一个字符,并将其作为一个 unsigned char 类型的值转换为 int 类型返回。
如果到达文件末尾或发生错误,则返回 EOF,它是一个特殊的值,通常定义为 -1。由于 EOF 的值不在 char 类型的范围内,因为char总是与无符号整数一一对应的,并没有负数的情况。因此需要使用 int 类型来保存 fgetc 函数的返回值,以便能够正确检测到文件末尾或错误。
2.3.2 C Streams: Block-by-Block I/O
一个以块为读取单位的程序,实现将input.txt文件内容拷贝达到output.txt中。
#define BUFFER_SIZE 1024
// copy contents from input.txt to output.txt
int main(void) {
FILE* input = fopen("input.txt", "r");
FILE* output = fopen("output.txt", "w");
char buffer[BUFFER_SIZE];
size_t length;
// length = fread(buffer, BUFFER_SIZE, sizeof(int), input);
length = fread(buffer, BUFFER_SIZE, sizeof(char), input);
while (length > 0) {
fwrite(buffer, length, sizeof(char), output);
length = fread(buffer, BUFFER_SIZE, sizeof(char), input);
}
fclose(input);
fclose(output);
}
2.4 Aside: System Programming
系统程序员应该始终保持警惕!否则可能导致间歇性的BUG。
我们应该像下面这样编写代码:
FILE* input = fopen("input.txt", "r");
if (input == NULL) {
// 打印字符串和错误消息
perror("Failed to open input file");
}
仔细检查返回值!你应该确保系统中的错误被系统地捕获和处理。
在课堂示例中,可能会对错误检查有所减少(为了简洁),但实际编码时请严格按照标准操作。换句话说,要按照我说的去做,而不是仅仅照搬课堂上展示的示例。
2.5 C High-Level File API: Positioning The Pointer
以下是C标准库中与文件流定位相关的一些函数:
int fseek(FILE *stream, long int offset, int whence);:将文件流stream的读写位置设置为偏移量offset,解释方式取决于参数whence。long int ftell(FILE *stream);:返回文件流stream当前的读写位置。void rewind(FILE *stream);:将文件流stream的读写位置重置到文件开头。
关于fseek()函数,它会根据参数whence的值(来自stdio.h中的常量)来解释offset参数,而whence参数有下面三种不同的常量值:
SEEK_SET:从文件开始(位置0)计算偏移量,开始位置+偏移量。SEEK_END:从文件结尾向前计算偏移量。SEEK_CUR:从当前位置计算偏移量,从当前位置+偏移量。
这些函数保留了高级抽象概念:文件流作为一致的字节序列。通过这些函数,我们可以在文件流中跳转到任意位置进行读写操作,从而实现更高效和灵活的文件处理。在编写复杂文件操作或处理大型文件时,这些功能尤为重要。
3. Low-Level File I/O: File Descriptors
3.1 Key Unix I/O Design Concepts
Uniformity – everything is a file:
-
通过open, read/write, close等操作,文件操作、设备I/O和进程间通信可以统一处理。
-
简化程序组合,例如,可以实现I/O的重定向,如:管道实现进程间通信:
find | grep | wc…
在使用前打开( Open before use):
- 这样可以在一开始就进行访问控制和争用处理。
- 为底层机制(例如,数据结构)初始化。
字节为单位( Byte-oriented):
- 即使是块传输,寻址也以字节为单位。
- 在内核眼中,它并不知道这些数据的含义,它只会逐个字节的去读取。
内核缓存读取( Kernel buffered reads):
- 无论是流设备还是块设备,内核都可以对读取过程进行缓存。当读取数据块时,操作系统会在执行过程中为其他任务让出处理器时间,实现多任务交替执行。
内核缓存写入( Kernel buffered writes):
- 内核允许将写入操作与应用程序的执行过程解耦。这意味着,某个写入操作完成与否并不影响应用程序的继续执行。
显示关闭( Explicit close):
- 当文件使用完毕后,需要显式地关闭文件描述符。这可以避免资源泄漏和其他潜在问题。
这些设计原则允许Unix系统中的文件、设备和进程间通信以统一、简洁的方式处理,从而大大提高了开发者在构建和组合程序时的便捷性和可靠性。在编写Linux系统程序时,理解这些原则对编写高效、准确的代码至关重要
3.2 Low-Level File I/O: Open/Create/Close
以下是在使用C语言处理文件时,通常使用的一些函数,低级的API就相当于直接调用系统调用了,只不过被C语言库包装了一下,防止用户直接访问内核的内存数据:
int open(const char *filename, int flags , mode_t mode]);:
- 打开文件并返回一个文件描述符。
-
函数的第一个参数 filename 是文件名,第二个参数 flags 控制打开文件的方式(例如:只读、只写、读写等),最后一个可选参数 mode 设置文件的权限(如User Group等等)。
int creat(const char *filename, mode_t mode);:
- 使用特定的模式(mode)创建一个新文件的权限并打开该文件,仅允许写操作。
-
此函数等价于 open(filename, O_WRONLY O_CREAT O_TRUNC, mode)。
int close(int filedes);:通过输入的文件描述符来关闭一个打开的文件。
open() 函数返回一个整数值,称为文件描述符(file descriptor)。
- 如果返回值小于 0 表示发生错误,这时全局变量
errno会被设置为相应的错误代码(可以通过查看手册页获取具体错误信息)。
关于文件描述符file descriptor的操作:
open系统调用在系统级的已打开文件表中创建一个已打开文件描述符的entry。- 内核中的已打开文件描述符对象代表着一个已打开的文件实例。
为什么给用户一个整数(文件描述符)而不是指向内核中文件描述的指针?
- 这是因为通过整数文件描述符,操作系统在用户空间和内核空间之间提供了一个抽象,使得用户程序无法直接访问内核空间的数据结构。这样的设计增强了系统的安全性和稳定性,防止了用户程序误操作导致的问题。
3.3 C Low-Level (pre-opened) Standard Descriptors
以下是关于文件处理 和 STDIN_FILENO(标准输入)、STDOUT_FILENO(标准输出)以及 STDERR_FILENO(标准错误)的宏以及与文件描述符相关的两个函数 fileno 和 fdopen 的简要介绍。
#include <unistd.h>引入<unistd.h>库,其中包含了标准文件描述符宏。STDIN_FILENO是一个常量宏,值为0。表示标准输入(通常是键盘输入)。STDOUT_FILENO是一个常量宏,值为1。表示标准输出(通常是屏幕输出)。STDERR_FILENO是一个常量宏,值为2。表示标准错误输出(通常也是屏幕输出)。
两个与文件描述符相关的函数:
int fileno(FILE *stream);:此函数接受一个文件流指针(FILE *类型)作为参数,并返回与该文件流关联的文件描述符(整数)。此过程可以将 stdio 文件流转换为文件描述符。FILE *fdopen(int filedes, const char *opentype);:此函数接受一个文件描述符(整数)和一个指定打开方式(opentype,例如:”r”、”w” 等)的字符串作为参数。通过给定的文件描述符生成一个新的文件流(FILE *)。此过程可以将文件描述符转换为 stdio 文件流。
在实际应用中需要根据不同的需求使用文件流(FILE *)或文件描述符(整数)进行文件操作。有时在处理文件时可能需要在这两种形式之间转换,那么这两个函数就非常有用了。
3.4 Low-Level File API:R/W
从打开的文件中读取数据: ssize_t read(int filedes, void *buffer, size_t maxsize);
- 这个函数使用文件描述符从打开文件中读取数据并将其存储在缓冲区中。最大读取字节数由
maxsize参数指定。实际读取的字节数可能小于maxsize。 - 函数返回实际读取的字节数;返回0表示到达文件末尾(EOF);返回-1表示发生错误。
向打开的文件中写入数据: ssize_t write(int filedes, const void *buffer, size_t size);
- 这个函数使用文件描述符向打开的文件中写入数据。
buffer参数指向要写入file中的数据缓冲区,size参数指明写入的字节数。函数返回写入的字节数。
在内核中重新定位文件偏移量(这与由高级 FILE 描述符为此文件保存的任何位置独立):
off_t lseek(int filedes, off_t offset, int whence);
- 这个函数可以在已打开文件中定位文件偏移量。
filedes是文件描述符,offset是偏移量,whence参数用于确定相对位置。 whence可以是SEEK_SET(从文件开头计算偏移量)、SEEK_CUR(从当前位置计算偏移量)或SEEK_END(从文件末尾计算偏移量)。函数返回新的文件偏移量。如果返回-1,表示发生错误。
3.5 POSIX I/O:Design Patterns
以下是关于文件操作的一些建议:
使用前打开(Open before use):在使用一个文件之前,需要先调用 open 或 creat 函数打开或创建文件。系统会在这一阶段进行权限检查,以及一些必要的初始化设置。
字节为单位读写(Byte-oriented):文件操作通常是以字节为单位进行的,这提供了最通用的数据处理方式。
- 操作系统将负责处理与实际设备的差异,例如,硬盘驱动器实际上是以数据块为单位存储数据的,但对用户程序而言,文件操作可以抽象成针对字节的读写操作。
显式关闭( Explicit close):在完成文件操作后需要调用 close 函数关闭文件。这一步释放文件占用的系统资源,确保对文件的修改得以保存,避免出现数据损坏或文件访问冲突的问题。
总结:在进行文件操作时,应先打开文件,然后使用字节为单位进行读写操作,并在完成所有操作后关闭文件。这些步骤有助于确保文件的安全性和完整性,同时使程序在各种操作系统和硬件环境下具有良好的兼容性。
3.6 POSIX I/O:Kernel Buffering
以下是关于在内核中进行读取和写入缓冲的一些说明:
内核中的读缓冲(Reads are buffered inside kernel):
- 内核会对文件的读操作进行缓冲,这是将文件操作统一抽象为
byte-oriented操作的一部分。 - 当进程等待设备执行读取操作时,进程会被阻塞,内核会允许其他进程在同一时间运行,从而提高系统的并发性能。
内核中的写缓冲(Writes are buffered inside kernel):
- 内核会对文件的写操作进行缓冲,写操作在后台执行。
- 当用户数据被完全交付给内核时,写操作视为完成,函数返回。
- 这样的设计可以让用户程序在写操作尚未真正完成时继续执行其他任务,提高了程序运行效率。
内核中的这些缓冲操作是对块设备(如磁盘)进行全局缓冲管理和缓存的一部分。
- 通常,内核会以磁盘块大小为缓存单元进行缓存。
- 当我们深入研究内核时,就会发现这种缓冲机制还有很多有趣的特性和优点。
总之,在内核中对读写操作进行缓冲有助于提高文件操作的效率,并统一各种设备的读写方式。同时,它还使得多个进程可以更好地并行运行,提高了整个系统的性能。
3.6 Low-Level I/O: Other Operations
以下是关于终端、设备、网络等特定操作以及一些高级文件操作的概述:
特定操作:某些操作仅适用于终端、设备或网络等特定领域。
- 例如
ioctl函数,可操纵底层设备特性。
复制文件描述符:
- 可以使用
dup2(int old, int new)或dup(int old)函数复制文件描述符。 dup2()函数将原文件描述符old复制到新文件描述符new。- 而
dup()函数只需要原文件描述符old,它会在可用的文件描述符中找到最小的整数作为新描述符。
管道(Pipes– channel):int pipe(int pipefd[2]); 函数用于创建一个管道。
- 管道是一种进程间通信(IPC)方式,它提供了一个双向或单向通信通道。
- 管道有两个文件描述符,写入
pipefd[1]的数据可以从pipefd[0]读取。
文件锁定(File Locking):
- 文件锁定功能可以防止多个进程同时访问/写入同一文件,从而确保数据正确性和一致性。
- 可以使用函数如
fcntl()或lockf()进行实现文件锁定。
内存映射文件(Memory-Mapping Files):
- 通过将文件映射到虚拟内存区域,将文件读写转换为对内存区域的读写。
- 这可以使用
mmap()和munmap()函数实现,进而提高大文件的访问速度。
异步I/O(Asynchronous I/O):
- 异步I/O(AIO)使得程序能在执行I/O操作时继续执行其他任务,而不必等待I/O操作完成。
- 在 POSIX 系统中,可以使用
libaio库实现异步I/O。
以上这些功能可以根据需要和特定场景选择使用,以实现更丰富多样的文件操作和进程通信方式。
4. How and Why of High-Level File I/O
4.1 High-Level vs. Low-Level File API-fread && read
fread() 和 read() 是两种不同层次的文件读取函数,它们有以下几点区别:
- 标准 I/O 库与系统调用:
fread()是 C 语言标准 I/O 库(stdio)中的函数,以文件流(FILE *)为操作对象。而read()是 POSIX 系统调用,它直接与操作系统内核交互,以文件描述符(整数)为操作对象。 - 缓冲区:
fread()使用内部缓冲区,其优势在于有更好的性能表现,特别是在高频率的读写操作中。内部缓冲区可减少实际的系统调用次数,从而降低资源消耗。而read()没有内部缓冲区,因此每次调用都会产生一个系统调用,进而可能引发更多的上下文切换和性能消耗。 - 错误处理:
fread()允许您检查是否发生错误,并针对错误设置特定的错误处理程序。而在read()中,您需要根据返回值判断是否发生错误,通过检查errno变量来了解更多关于错误的信息。 - 文本和二进制模式:
fread()支持文本模式和二进制模式。在文本模式下,Windows 上的换行符可能在读取时自动转换为 Unix 风格(”\r\n” 转换为 “\n”)。而对于read(),它会直接读取字节,不做任何转换。 - 使用场景: 在速度和可移植性要求较高的应用中,
fread()可能是更好的选择,它提供了易于使用的错误处理、自动缓冲区管理和文本/二进制模式支持。而在需要精确控制文件访问方式和性能要求较高的情况下,read()可直接与操作系统内核交互,提供了更精细的文件操作控制。
总结:fread() 和 read() 在不同方面有所差异。fread() 是标准 I/O 库中的高级文件读取函数,易于使用、具有内部缓冲区和更丰富的错误处理功能,适用于速度和可移植性要求较高的场景。而 read() 是低级系统调用,操作更直接,适用于需要精确控制文件访问和优化性能的场景。根据不同需求和场景选择相应的函数。
4.1.1 Diff at buffer:More details
关于 fread() 和 read() 之间缓冲区的差异,我们可以更详细地分析如下:
- 类型:
fread()使用用户空间的缓冲区,而read()使用内核空间的缓冲区。fread()是标准 I/O 库函数,其缓冲区由库在用户空间管理。read()是系统调用,其缓冲区由操作系统内核进行管理。 - 管理:
fread()的缓冲区管理自动进行。当执行fread()时,标准 I/O 库自动分配和填充缓冲区。当缓冲区为空或关闭文件时,库会自动将缓冲区的内容刷新到磁盘。而对于read(),因为没有内部缓冲区,每次读取请求都会触发系统调用和内核空间数据传输,无需用户处理缓冲区细节。 - 效率:
fread()通过缓冲区可以减少系统调用次数,降低 I/O 操作对系统性能的影响,特别是在高频率文件操作场景中。而read()没有使用缓冲区,每次操作都直接与内核进行交互,频繁的系统调用可能导致性能下降。 - 灵活性:
fread()提供了有关缓冲区的函数如setbuf(),setvbuf()和fflush(),可根据需求选择和调整缓冲区大小,设置自动刷新等。read()没有内部缓冲区相关功能,如需要缓冲,用户需要在应用程序中自行实现。
总结:fread() 和 read() 在缓冲区方面的差异主要体现在类型、管理、效率和灵活性等方面。fread() 的缓冲区由标准 I/O 库自动管理,提供了较高的 I/O 效率,同时允许用户根据需要调整和设置缓冲区。
而 read() 没有内部缓冲区,直接与操作系统内核交互,应用程序如需缓存等功能,需要自行实现,用户需要自己分配缓冲区,从而实现更精细的控制。
根据具体需求和场景选择合适的函数。
4.1.2 Printf() && write().
正如您所提到的,在实际应用中,C 标准库函数(如 printf())和系统调用函数(如 write())在行为上具有不同的特性。
标准 I/O 库(如 fread() 和 printf())中的流缓存在用户内存中。这意味着,缓冲区管理和优化由库负责,并使程序在进行I/O操作时具有更高的性能。然而,这也可能导致某些情况下输出不如预期般直观。
例如,在如下例子中,printf() 在打印时会将两个字符串先写入缓冲区,直到遇到换行符或手动刷新时才会显示输出结果。因此,两个字符串会一次性输出。
printf("Beginning of line ");
sleep(10); // sleep for 10 seconds
printf("and end of line\n");
与此相反,文件描述符的操作(如 read() 和 write())会立即对外部可见。这是因为这些系统调用没有内部缓冲区,而是直接与内核交互。所以在您给出的例子中,write() 在每次调用时会立即执行,因此 “Beginning of line” 会在等待10秒后 “and end of line” 之前输出。
write(STDOUT_FILENO, "Beginning of line ", 18);
sleep(10);
write("and end of line \n", 16);
这些差异帮助我们理解何时使用标准 I/O 库和何时使用系统调用更为合适。在关注性能和易用性的场景下,标准库函数更有优势。然而,在需要立即可见、直接控制的情形下,系统调用函数是更好的选择。不过,如果希望使用标准库函数同时输出立即可见,可以使用 fflush() 函数刷新缓冲区。
4.2 What’s in a FILE
FILE * 是由 fopen() 函数返回的一个指针,它指向一个 FILE 结构体,代表一个打开的文件流。FILE 结构体包含了与文件操作相关的各种信息。以下描述了 FILE 结构体中的一些主要组成部分:
- 文件描述符(
File descriptor):该文件描述符实际上是一个整数,由系统调用open()返回。在文件操作过程中,文件描述符用于与内核进行接口交互,代表与操作系统内核中打开的文件的唯一标识。 - 缓冲区(
Buffer):FILE结构体中包含一个缓冲区数组。标准 I/O 函数(如fread()和fwrite())利用该缓冲区来优化文件读写性能。当缓冲区满或刷新时,数据会被写入文件,当缓冲区为空且需要读取时,数据会从文件填充缓冲区。 - 锁(
Lock):这用于对文件流进行同步访问,防止多个线程在并发执行时对同一个FILE进行操作。这可以确保数据的正确性和一致性。
除了上述内容之外,FILE 结构体还包含其他与文件操作相关的信息,如文件指针、错误标志、文件访问模式等。然而,在理解和使用 FILE 指针的过程中,关注文件描述符、缓冲区和锁这几个关键部分是很有用的。
4.3 FILE Buffering
当您调用 fwrite 函数时,会发生以下操作:
- 数据写入
FILE的缓冲区:您提供的数据会首先写入文件流(FILE)的缓冲区。 - 刷新缓冲区:如果
FILE的缓冲区已满,那么缓冲区会被刷新。刷新意味着缓冲区中的数据会被写入底层的文件描述符,即实际文件。 - 更频繁的刷新:C 标准库可能会在某些情况下更频繁地刷新
FILE。例如,当缓冲区中出现特定字符(如换行符)或者调用fflush()函数时,库会主动刷新缓冲区。
编写代码时,关于 FILE 缓冲区刷新的处理,建议尽可能采用最弱的假设:
- 不要假设特定周期或条件下缓冲区会自动刷新。
- 如果需要确保写入数据立即可见,手动调用
fflush()以强制刷新缓冲区。 - 设计代码时考虑程序在不同平台、操作系统和编译器上的兼容性,因为刷新行为可能因实现而异。
通过这样的做法,您可以确保编写的代码对缓冲区刷新行为的设想不会对程序的正确性产生负面影响。
4.3.1 Example1:Not sure result of x
char x = ‘c’;
FILE* f1 = fopen(“file.txt”, “w”);
fwrite(“b”, sizeof(char), 1, f1);
FILE* f2 = fopen(“file.txt”, “r”);
fread(&x, sizeof(char), 1, f2);
在这种情况下,X的结果可能会是不确定的,这是由于 FILE 缓冲区在何时刷新的问题。您在 fwrite() 操作后,可能会遇到以下两种情况:
fread()函数看到最新写入的 ‘b’:如果在读取操作前,缓冲区已刷新,那么fread()函数将成功读取到 ‘b’。在这种情况下,变量x变为 ‘b’。fread()函数看到文件末尾:如果在读取操作前,缓冲区未刷新,那么fread()函数可能只能看到文件末尾。也就是fread()没有读取到任何字符,变量x仍为 ‘c’。
4.3.2 Example2:sure result of x-fflush()
char x = ‘c’;
FILE* f1 = fopen(“file.txt”, “wb”);
fwrite(“b”, sizeof(char), 1, f1);
fflush(f1); //加入了主动刷新数据到磁盘的操作
FILE* f2 = fopen(“file.txt”, “rb”);
fread(&x, sizeof(char), 1, f2);
现在x一定可以读到b了,因为我们调用了fflush()操作:
在C++中,当我们调用fwrite函数后,数据会被写入用户缓冲区。然后,当你调用fflush函数时,数据会从用户缓冲区流向内核缓冲区,然后再流向磁盘缓冲区(如果存在的话),最后写入物理磁盘文件。这个过程确保了数据的安全写入。请注意,这个过程可能会因操作系统和文件系统的不同而有所不同。在某些情况下,可能会直接从内核缓冲区写入物理磁盘,跳过磁盘缓冲区。但总的来说,就是这么个流程。
调用fflush函数后,数据通常会被从用户缓冲区移动到内核缓冲区,然后可能会被移动到磁盘缓冲区(如果存在的话)。最后,数据会被写入物理磁盘文件。所以,当fflush调用结束时,数据应该已经在物理磁盘文件上了。
但请注意,这个过程可能会因操作系统和文件系统的不同而有所不同。在某些情况下,可能会直接从内核缓冲区写入物理磁盘,跳过磁盘缓冲区。但总的来说,当fflush调用结束时,数据应该已经安全地写入了物理磁盘文件。
调用 fflush() 时,数据流的变化过程可以概括为:用户缓冲区 > 内核缓冲区 > 磁盘缓冲区(如果有的话)> 物理磁盘文件这个过程描述了数据如何从用户空间的文件流缓冲区传输至实际的磁盘文件:
- 用户缓冲区:这是由文件流(
FILE结构体)在用户空间管理的缓冲区。fwrite()等标准 I/O 函数将数据写入这个缓冲区。 - 内核缓冲区:当调用
fflush()时,数据从用户缓冲区传递到内核缓冲区。内核会处理数据并准备将其写入文件系统。 - 磁盘缓冲区:根据操作系统和文件系统的实现,内核可能会将数据写入磁盘缓冲区。磁盘缓冲区用于优化磁盘 I/O 操作,例如:合并多个写入请求以提高性能。
- 物理磁盘文件:最终,数据会被实际写入物理磁盘文件。这个过程可能会受到磁盘调度算法和硬件性能等因素的影响。
通过了解这个数据流过程,您可以更好地掌握文件 I/O 操作的底层机制,以便在实际编程过程中做出明智的决策。请注意,操作系统、文件系统和硬件的具体实现可能会导致实际过程的差异。
4.4 Writing Correct Code with FILE
您的代码应该在 C 标准库刷新其缓冲区时表现出正确的行为,为此可以遵循以下注意事项:
- 根据需要添加
fflush()调用,确保在需要时将数据写入文件。在关键数据写入或者在写入操作后需要立即执行读取操作的场景中,使用fflush()可以确保数据立即可见。 - 调用
fclose()会在释放内存和关闭文件描述符之前刷新缓冲区。因此,如果您在操作文件时使用了 C 标准库,建议在完成所有读写操作后调用fclose(),以确保所有数据已写入文件。
使用低级文件 API(如 read() 和 write() 系统调用)时,不会遇到缓冲区刷新问题,因为这些调用不涉及用户空间的缓冲区管理。在这种情况下,以下规则适用:
- 在
write()完成后,数据对于任何后续读取操作都是可见的,因为这些系统调用直接与内核交互,没有额外的用户空间缓冲区。
请注意,在编写代码时,了解文件 I/O 机制及其底层行为是十分重要的,这样才能确保程序行为的正确性和数据的一致性。在使用 C 标准库还是低级文件API时,根据实际需求和场景调整代码以满足正确的缓存管理和刷新策略。
4.5 Why Buffer in Userspace?
用户空间缓冲区的存在是为了降低系统调用的开销,提高应用程序的性能。以下是详细解释:
系统调用(Syscalls)相较于普通的函数调用具有更高的开销,大约高出 25 倍。系统调用涉及从用户空间切换到内核空间的上下文切换,这需要时间并可能导致 CPU 缓存失效,从而增加延迟。
如果逐字节读取或写入文件,不使用用户空间缓冲区,那么在频繁地调用系统调用时性能将会受到很大影响,这可能导致 I/O 速度降低,最大吞吐量可能仅为每秒几兆字节。
- 使用C语言库中的fread/fwrite调用,函数会事先申请一个buffer,一次fread会直接从内核读取一个缓冲区大小的数据,按需慢慢地发送给用户,直到这个buffer里的数据用尽,才会再次向内核请求数据;而不是每次用户读取都需要进行一次系统调用;
- fwrite也是直到要写入的数据写满一个用户buffer,才会把buffer里的数据发给内核。
当使用用户空间中的缓冲区(例如使用 fgetc 这样的函数),程序可以将数据在用户空间中进行缓存、组合或分割,然后将其批量发送给内核。这样可以减少系统调用的数量,提高程序的运行速度,很大程度上提高 I/O 性能,使得吞吐量能够跟上现代 SSD 的速度。
总之,用户空间缓冲区的存在主要是为了降低系统调用的开销,从而提高 I/O 性能。通过在用户空间对数据进行缓存和批处理,可以抵消系统调用的高开销,并使应用程序能够更加高效地读取和写入文件。
4.6 Why Buffer in Userspace? Functionality!
将缓冲区保留在用户空间还有助于提供更灵活的功能。原因如下:
- 系统调用操作相对简单:将复杂操作保留在用户空间可以简化操作系统的实现。系统调用通常负责底层的基本操作,而更高级的功能可以在用户空间实现。
- 示例:内核中没有“读取直至新行”的操作。这是因为内核对格式保持中立,它不关心文件的具体内容和格式。解决方案是在用户空间中实现这样的功能。例如,可以进行一次大的
read系统调用,然后在用户空间查找第一个新行。
这就是为什么存在像 fgets() 和 getline() 这样的高级函数。它们在用户空间实现,并利用底层的系统调用以灵活且高效的方式读取和处理文件。
通过在用户空间实现高级功能并使用缓冲区,程序员可以更容易地编写灵活的文件操作代码,同时仍然能够充分利用操作系统提供的底层功能。同时,这种设计可以保持操作系统的简单性和易于维护。
5. Process State for File Descriptors
5.1 State Maintained by the Kernel
回顾一下,在成功调用 open() 函数时:
- 用户会收到一个文件描述符(整数)-
A file descriptor (int)。 - 内核中会创建一个打开的文件描述(
open file description)。
对于每个进程,内核会维护从file descriptor(user)到open file description(kernel)的映射关系:
- 在后续的系统调用(如 read())中,内核会使用文件描述符查找打开的文件描述,然后根据它来处理系统调用。
请注意,在这个过程中,文件描述符充当了用户空间和内核空间之间的标识符,它告诉内核应该对哪个打开的文件执行 I/O 操作。这个机制使得用户程序能够与操作系统内核进行通信,从而实现文件读写等功能。而内核会负责记录这些文件状态,并针对具体系统调用执行相应操作。
open file description是一个内核维护的结构体,一个打开的文件描述中包含哪些内容呢?对于我们而言,最重要的两个部分如下:
inode:在磁盘上找到文件数据的信息(索引节点),后面会详细讲解。f_pos:文件中的当前位置。
当一个文件被成功打开时,内核会在内存中创建一个关于该文件打开描述的记录。其中,inode 是文件在磁盘上的索引节点,它存储了文件的元数据,如文件大小、创建时间,以及文件存储在磁盘上的块地址信息。通过这些信息,内核可以准确地在磁盘上找到和操作文件的实际数据。
另一方面,f_pos 用于记录文件中当前的位置。在读取和写入文件过程中,f_pos 会不断更新以反映操作的进度。例如,在进行 read() 或 write() 系统调用时,内核会根据 f_pos 确定从文件的哪个位置开始执行操作。当操作完成后,f_pos 会相应地更新,以便下次操作能正确地从上次停止的地方继续执行。这使得文件系统能够保持访问的连续性和正确性。
5.2 Abstract Representation of a Process

在一个进程中,我们执行的程序有Open("foo.txt")命令,返回给进程一个文件描述符3,而在内核空间里记录着一个映射:File Descriptor->Open File Description,用户可以通过这个映射去操作文件,而打开文件描述这个结构题也会实时记录用户的行为。
为什么文件描述符不是从0,1,2开始,因为之前我们说过,在系统开机后,0,1,2这三个文件描述符就被占用了,分别被0->stdin,1->stdout,2->stderr使用。
当我们调用close(3)时,因为目前只有一个文件描述符指向打开的文件描述结构体,所以一旦close后,该打开的文件描述的引用变为0,一般情况下系统也会释放这个打开的文件描述结构体。
5.2.1 Instead of Closing, let’s fork()!
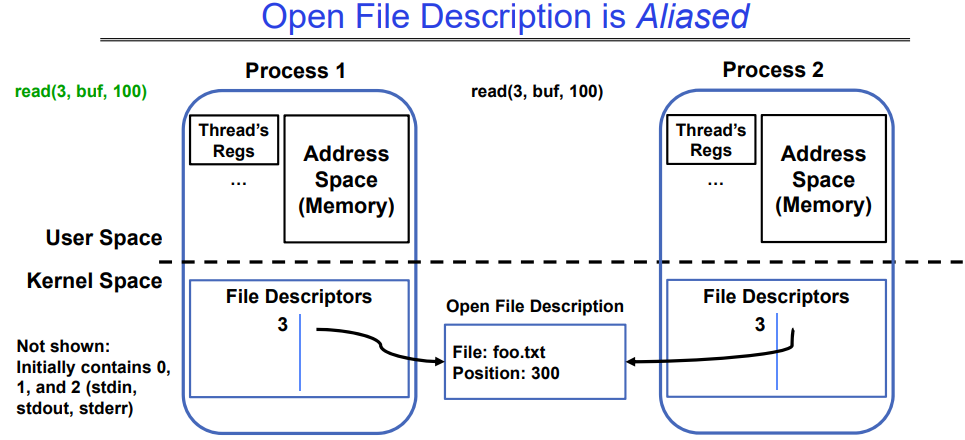
当我们从process1执行fork()生成process2后,由于是完全复制,进程2与进程1有相同的文件描述符,指向同一个打开的文件描述,因此他们共用同一个文件偏移量指针。
即使我们在某一个进程中,调用了close()操作,影响的是对Open File Description的count_ref–,但是不会回收,不会影响进程2对这个打开文件描述的使用。
获得旧文件的新的文件打开描述的唯一方法就是fork()的新进程中再次调用open("foo.txt")函数,这样就会创建一个新的打开的文件描述。
为什么OS允许父子进程共享相同的文件描述符列表?
5.3 Why is Aliasing the Open File Description a Good Idea?
共享相同的File Descriptor具有以下优点:
允许在进程间共享资源:
- 通过文件描述符,不同的进程可以访问相同的文件或共享资源,使得进程间协同工作更加容易。
统一的接口:
- 文件描述符为各种类型的 I/O 设备提供了统一的接口.
-
例如磁盘上的文件、设备(终端、打印机等)、网络(套接字)以及本地进程间通信(管道、套接字)。
- 这有助于简化不同类型 I/O 设备的操作和管理工作。
基于系统调用:
- 文件描述符的实现基于系统调用 open()、read()、write() 和 close(),使程序员能够方便地使用这些调用来执行对应的文件和设备操作。
文件描述符为操作系统中的文件系统和设备操作提供了一种灵活且通用的处理方式,简化了应用程序与操作系统内核之间的交互,从而提高了操作系统的可用性和易用性。
5.3.1 Example: Shared Terminal Emulator
当您使用 fork() 创建一个新进程时,父进程和子进程的 printf 输出都会发送到同一个终端,因为他们都共享相同相同的文件描述符1->stdout。这对于作业2来说非常重要。
这是因为在 fork() 创建子进程时,子进程会继承父进程的文件描述符,并共享相同的文件(例如,打印到标准输出的设备文件,如终端)。
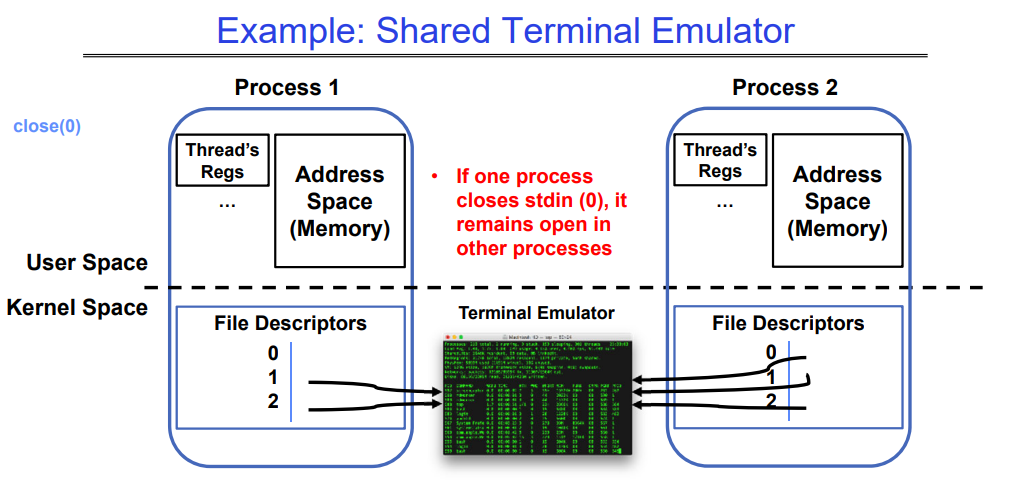
5.3.2 Other Examples
在 fork() 之后共享网络连接:
- 这允许在不同的进程中处理每个连接,我们将在下次课程中进一步探讨这个主题。
共享管道访问:
- 这对于进程间通信非常有用,也适用于编写一个 shell(例如,作为第二次作业的内容)。
5.4 Other Syscalls: dup and dup2
它们(函数 dup() 和 dup2())允许您复制文件描述符。
但打开的文件描述保持别名关联。
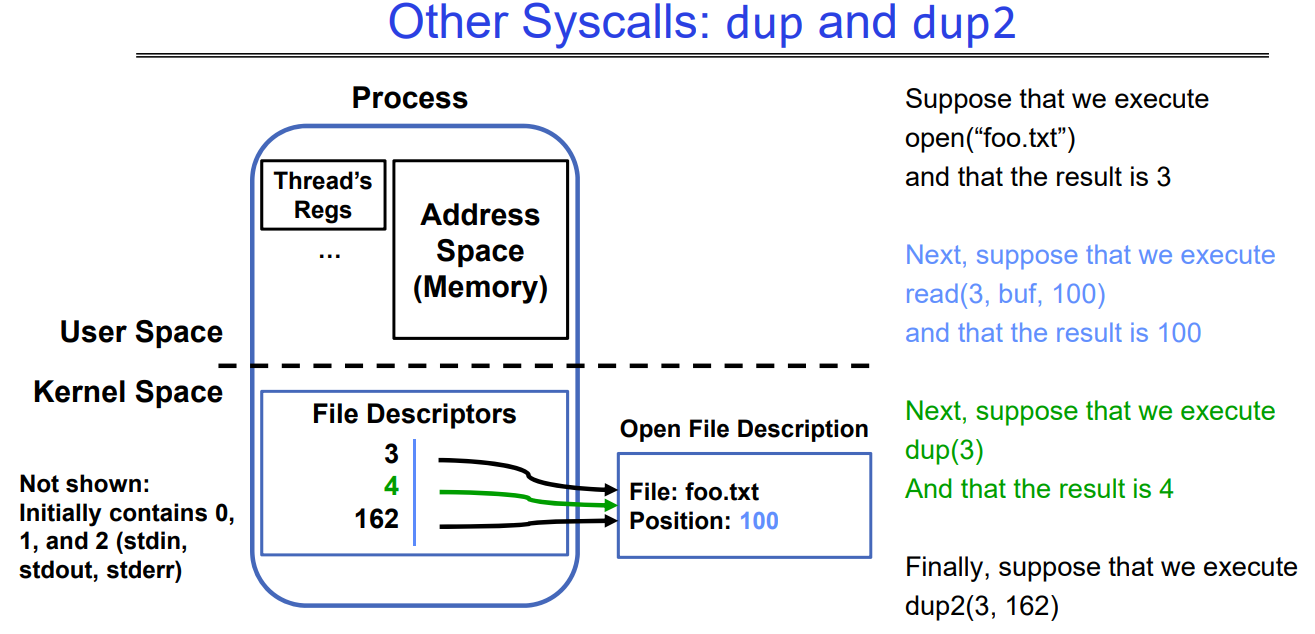
dup() 和 dup2() 系统调用可以创建一个已经打开文件描述符的副本(新的文件描述符)。这样,您可以使用这个新的文件描述符来访问同一个文件或设备,而无需改变原始文件描述符的状态。
尽管新的文件描述符与原始文件描述符具有不同的整数值,但它们都引用同一个打开的文件描述。这意味着它们共享相同的文件状态,如当前文件位置(f_pos)等信息。
使用 dup() 和 dup2() 在不同的场景下可以更加灵活地进行文件和设备操作。例如,在进程间通信中,您可以创建一个文件描述符的副本,以便不同进程可以独立地访问相同的资源,同时保持它们的状态同步。通过这种方式,多个进程可以共享相同的打开文件描述,实现进程间资源共享和协作。
6. Some Pitfalls with OS Abstractions(重要)
6.1 Don’t fork() in Multi-threaded Processes
除非您打算在子进程中调用 exec():执行别的程序,否则请勿在已具有多个线程的进程中调用 fork()。
在多线程环境中调用 fork() 可能会导致的问题:
当在多线程进程中调用 fork() 时,其他线程(即未调用 fork() 的线程)会消失。这可能会导致一系列问题:
- 如果消失的线程中有正在持有锁的线程,怎么办?
- 如果消失的线程中有正在修改数据结构的线程,怎么办?
- 由于线程消失,这些资源无法正确清理!
如果在子进程中调用 exec(),则是安全的,因为 exec() 将替换整个地址空间。
- 调用 exec() 会用新的程序映像替换子进程的地址空间,从程序入口重新开始执行。这样,在子进程中,原有的多线程上下文不再存在,因此不必担心这些消失线程所带来的潜在问题。
总之,在多线程进程中使用 fork() 存在风险,应谨慎处理。尤其是在不调用 exec() 的情况下,务必确保了解消失线程可能带来的潜在问题,并确定能够正确处理资源和状态。如果在子进程中调用 exec(),则可以降低 fork() 带来的风险,因为整个地址空间将得到重新设置。
6.1.1 Example1
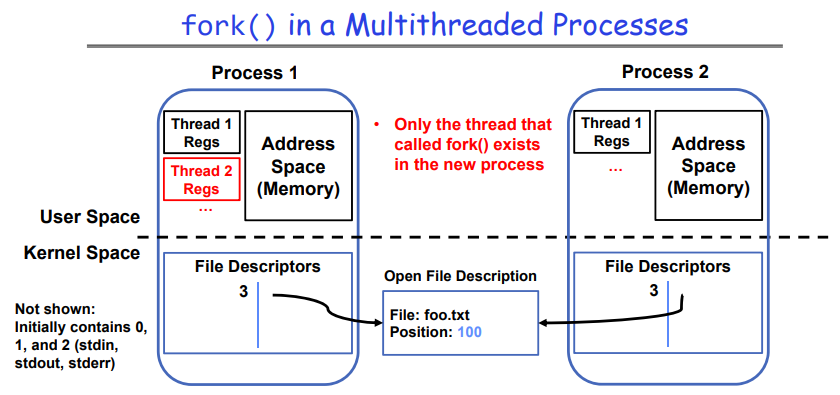
在子进程中只有一个线程,即调用 fork() 的线程。其它线程在子进程中消失。
当在多线程应用程序中调用 fork() 时,子进程将仅继承那个调用 fork() 的线程。而父进程中的其他线程,在子进程里面就不存在了。这可能导致子进程中的执行逻辑和资源管理发生问题,因为子进程无法访问到那些其他线程以及它们创建的资源。
因此,在含有多个线程的进程中使用 fork() 是一种不推荐的行为。在这种情况下,最好使用其他进程或线程管理方法,以确保正确的资源共享和程序逻辑执行。
6.2 Don’t Mix Low-Level And High-Level File I/O carelessly
请勿随意混用低级和高级文件 I/O。
-
低级文件 I/O(如 open()、read()、write() 和 close() 系统调用)直接与操作系统和内核进行通信,为程序提供更为底层的文件操作能力。
-
相比之下,高级文件 I/O(如 C 标准库中的 fopen()、fread()、fwrite() 和 fclose() 函数)在底层系统调用之上提供了额外的封装和抽象,为程序员提供更为友好和易用的接口。
在同一个程序中混用低级和高级文件 I/O 可能会导致以下问题:
- 缓冲区管理混乱:高级文件 I/O 库通常会在内部实现自己的缓冲区管理,如输入和输出缓冲。如果同时使用低级文件 I/O,可能会导致缓冲区数据不一致,从而导致读写错误和数据丢失。
- 跨平台兼容性问题:高级文件 I/O 函数通常具有更好的跨平台兼容性,因为它们会在不同操作系统之间提供统一的实现。但是,混合使用低级和高级文件 I/O 可能会导致跨平台兼容性问题,因为低级系统调用可能会因操作系统的差异而表现出不同的行为。
- 代码维护困难:在同一程序中混用低级和高级文件 I/O 很可能会导致代码理解和维护变得复杂。为了保持代码的清晰和一致性,最好在整个程序中坚持使用一种方法(高级或低级)。
总之,为了确保程序的稳定性、兼容性和可维护性,请务必谨慎使用低级和高级文件 I/O,并在可能的情况下遵循一致的编码和设计风格。
6.2.1 Examples
在这个例子中:
char x[10];
char y[10];
FILE* f = fopen("foo.txt", "rb");
int fd = fileno(f);
fread(x, 10, 1, f); // 从 f 中读取 10 个字节
read(fd, y, 10); // 假设从偏移量 10 处开始返回数据
问题:从文件中读取哪些字节到 y?
-
A. 字节 0 到 9
-
B. 字节 10 到 19
-
C. 以上都不是?
答案:C(以上都不是)。
在这种情况下,fread() 可能会将较大块的文件数据读入用户级缓冲区(注意这个缓冲区并不是上面声明的X,而是C语言库给fread分配的一块巨大的用户缓冲区),这可能包括整个文件。
当你再使用 read() 函数时,由于 fread() 有自己的缓冲区管理,而低级系统调用 read() 与之不兼容。因此在这种情况下,无法确定在缓冲区 y 中从文件读取的字节是从哪个偏移量开始的。这就是混用高级和低级文件 I/O 可能导致的问题之一。为避免这类问题,建议在编程中使用其中一种文件I/O方式,以确保稳定性和一致性。
6.3 Be careful with fork() and FILE*
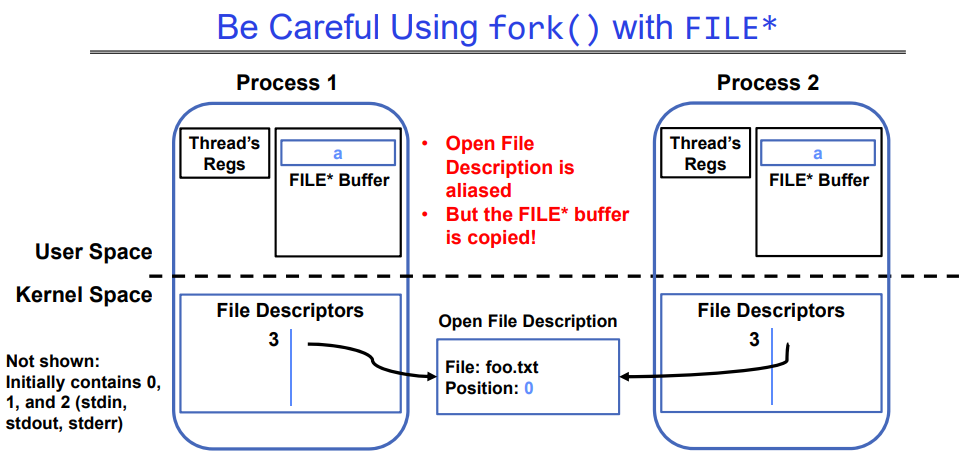
在此示例中:
FILE* f = fopen("foo.txt", "w");
// fwrite() 操作是否调用fflush操作取决于..
fwrite("a", 1, 1, f);
// 子进程只会执行fork()下面的代码逻辑(包括fork()操作本身),而不是从头开始执行
fork();
fclose(f);
在所有进程退出后,foo.txt 中的内容是什么?
可能是 a 或 aa。
根据在 Linux 中观察到的情况,通常结果是 aa。原因如下:
当 fork() 被调用时,子进程继承了父进程的资源,包括打开的文件描述符。在这个情况下,子进程也会有一个指向 “foo.txt” 的文件指针。由于 fwrite() 缓冲区在 fork() 之前已经保存了字符 “a”,而子进程继承了同样的 FILE 结构和内容,因此两个进程都有相同的内容在缓冲区中。
当两个进程分别关闭它们各自的 FILE 指针时,缓冲区中的内容将被刷新到磁盘上的 “foo.txt” 文件。因为 fclose() 函数会将缓冲区的内容写入文件并关闭文件指针,所以两个进程将相同的内容 “a” 写入同一个文件 “foo.txt” 中,导致文件中最终包含 “aa”。
不过请注意,这种行为并不能保证在所有平台和实现中都一致。理想情况下,应该避免在多进程中共享文件资源,或者使用其他同步和协同工具来管理这种共享。如下图所示:
7. Conclusion
7.1 OS 文件系统图
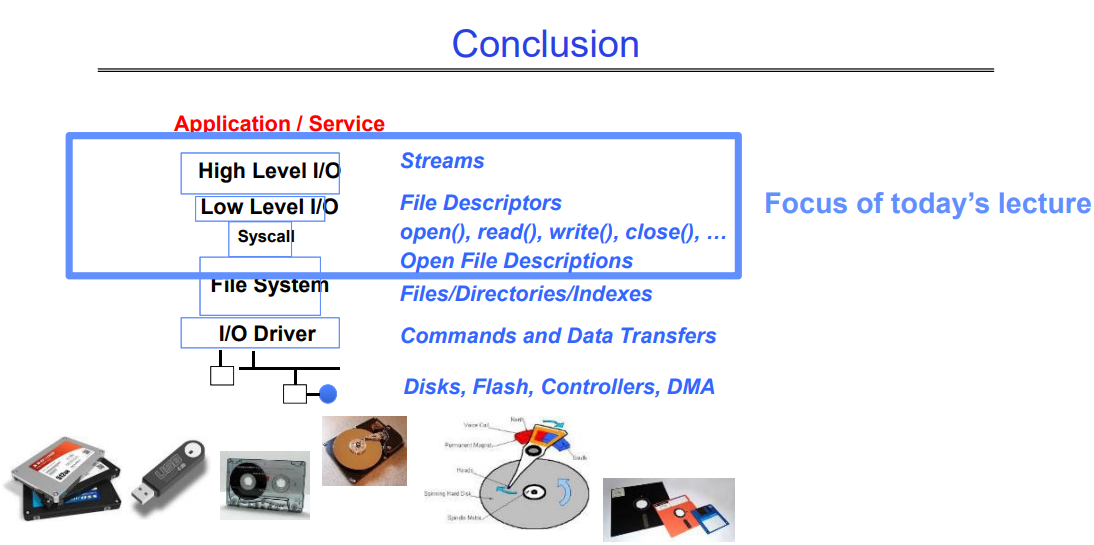
7.2 conclusion of today’s lecture
POSIX 思想:“一切皆文件”
- POSIX操作系统设计中的一个核心原则是将各种资源(如文件、设备和管道)视为文件,以简化编程和操作。
通过 open/read/write/close 管理各种 I/O
- 文件操作的四个基本功能(打开、读取、写入和关闭)提供了一个简单且通用的接口,用于处理各种 I/O 操作。
在进程控制块(PCB)中添加了两个新元素:
- 从文件描述符(
file descriptor)到打开文件描述(open file description)的映射- 文件描述符是用户请求内核文件操作的桥梁,打开文件描述是一个内核数据结构。
- 文件描述符与打开文件描述之间的映射使操作系统能够为每个进程管理其打开的文件。
- 当前工作目录
- 当前工作目录存储在 PCB 中,以便进程可以找到和操作相对路径下的文件。
这些基本概念和设计原则有助于理解 POSIX 兼容操作系统(如 Linux)中的文件和 I/O 系统,以及如何利用它们进行有效的编程。