1. Functions
Functions和String这些内容在教材第二章与第三章。如果想深入了解可以去去看看教材。
Free floating function:在匿名空间中,只能在单个源文件中进行访问,可以简单理解为是非类成员函数。
1.1 Default parameters(默认参数)

我们可以给C++的function设置默认值,但是所有有默认值的参数都必须放在参数列表的末尾。即不能是前面或中间部分穿插默认值参数,只能全部放在列表末尾(最右边),否则会造成歧义。
这一功能C++有,但是Java没有。
1.2 Declaration order(声明顺序)
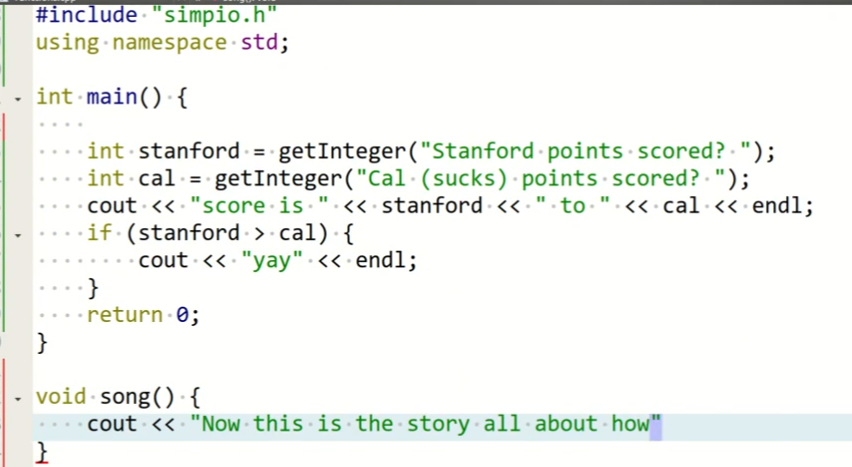
这里song一切的函数必须在使用之前就被声明或者被定义,比如说:这里song()函数在main下面被定义,在main里调用song()的话,会编译错误,它会找不到song()函数的定义。
解决方法是在main上面声明这个函数:void song();我们称它为
Function prototype,函数原型。
这个奇怪的问题只有c++有,Java则不会有这种愚蠢的错误。
1.3 Function prototype(函数原型)

承接1.2中的Delaration order,如果我们在main函数下面写了Function definition,那么我们必须在main函数上面写上该函数对应的Function prototype,c++编译器在编译时才能找到这个函数。
当把函数原型与函数定义分开,而我们又想声明默认参数,那么我们只需要在函数原型中写出默认参数的值即可,不需要在函数定义中再重复的做一遍,否则会编译不通过。
此外,当我们定义的函数过多时,我们会把函数原型与函数定义分开存放:我们一般会选择把所有的函数原型放在一个.h文件中,之后在一个单独的.cpp文件中写入对应的函数定义。之后有文件需要使用这些定义函数时,只需要导入函数原型所在的文件(.h文件)。
问:当分开存放时,为什么直接导入函数定义所在的文件,而是选择导入函数原型所在的文件呢?
答:<u**>b文件中 #include的本质就是把文件a拷贝一份放到b里面。**</u>假设我们有b与a两个文件,且b include a,当我们在一个文件中同时link a与b时,就会出现重定义的问题,这是过不了compile的,可能在这里有些抽象,后面碰到具体问题时就明白了。
即如果直接#include函数定义文件,那么会出现将函数定义文件与函数原型文件进行link,会出现函数定义文件的copy,进而会产生重定义问题。
但是
using namespace xxx;不会发生重定义问题,因为这就是一个声明,编译运行是可以通过的。
1.4 namespace与#include<>
在#include
如果在main中使用了一个成员,编译器查找顺序是:当前文件中找->using namespace XXX,在命名空间XXX中找。优先在当前文件中找,若没找到,才会退而求其次的去我们用的命令空间中找。
如果我们没有声明一个namespace{}并在里面定义一些变量、函数、类,那么我们声明变量、函数、类这些就都在global namespace中。106X中不建议写太多的自定义namespace,此外,如果我们using 一个namespace,那么我们应该对其包含的成员有一些了解。但是如果在做一个很大的项目,项目中有很多文件,那么去自定义一个namespace会更适合当前的情况。
2.Value/reference semantics
值语义与引用语义:在c++中,当我们定义函数时,参数的语义类型决定了我们在函数体内对参数进行修改时是否会影响到传入的变量本身。值语义不会影响,引用语义则会影响到传入的变量本身。
2.1 Value semantics(值语义)

在java与c++中,当如同Int,double(基本数据类型)这样类型的变量被作为参数传递时,他们的值只会被复制一份到当前的函数中,对这些复制的参数的修改不会影响到那些传入的变量本身的值,如上面的例子所示。
在很多编程语言中,如果我们传递的是对象(object),例如array、list这样的类型,那么他们就会被正常的交换,即在函数中的操作会影响到传入的变量本身的值。
这一块内容在后续的课程中会深入讨论。
当然还有Reference semantics-引用语义。编程语言会根据数据的类型来决定使用哪种语义,但是在C++中我们可以自行决定使用哪种语义。
2.2 Reference semantics(引用语义)

引用语义,如果我们在声明函数的参数列表时,在type后面加上了&-引用符号,那么函数就会把该函数的参数列表与我们传入的变量的内存地址链接起来,此时在函数内部对参数做的修改会直接影响到传入的变量本身。
虽然指针可以做到与引用语义相同的功能,但是使用指针会更不安全,更容易导致程序崩溃,相比来说引用语义则显得更加简单与可控。
2.3 Output Reference parameter
引用语义可以将传入的参数作为输出结果的参数,当我们需要返回的值不止一个时,可以考虑使用引用语义来保存我们要返回的值,就可以实现多个返回值的功能。要谨慎的使用引用语义,不要滥用这个特性,否则会有很多意想不到的值被修改,我们要确保我们知道哪些值会被修改。
2.4 Value semantics or Reference semantics
除了上述情况外,我们如何决定何时使用值语义、何时使用引用语义。一般而言,不需要在意这些,因为这不会给程序的性能带来明显的影响,但是当我们传入的参数是一个很大的array、list、class时(大对象),而我们不想花大量的时间去复制它,那么此时改为引用语义是值得的。对于一般的大小的对象,则不需要特意使用引用语义。
大对象一般指非基本数据类型的对象。
2.5 Value semantics-deep/shallow copies
当我们采用值语义进行参数传递时,我们可以使用deep copies(深拷贝)或shallow copies(浅拷贝)。默认情况下,都是采用浅拷贝。比如说复制了一个指针,那么复制出的指针与原先的指针依然指向同一个对象。后面的课程会对这块内容进行进一步深入。
2.6 summary of reference semantics

引用语义的好处:
- 可以实现让我们一次性返回多个值;
- 当我们传入的值是非基本对象时,这可以避免对该对象的拷贝,节省一些资源。
引用语义的坏处:
- 如果不查看原函数定义,我们很难知道函数中哪些参数是引用语义、哪些参数是值语义。
- 有时候使用引用语义会比值语义更慢,因为我们在使用时,需要创建与之相关的内存指针和一些别的东西;
- 不能把
literal value(右值、字面值)作为引用语义参数传入,只能将变量作为引用参数传入,因为传入的引用语义参数实际上是该变量位于内存中的位置。
3. Procedural decomp.(程序分解)

我们希望写的每个function都是一个独立的功能,并且与其他的function没有必然的联系,可以单独的调用每一个函数,我们希望main函数内可以显式的调用绝大部分函数。
而不是说像下面那个糟糕的例子一样:这种风格被称为函数链,这会导致函数之间耦合极为严重,很难将这些函数分开来并单独运行。如果method4出现了问题,那么其他的所有功能都无法正常的执行,method1,method2,method3都无法正常的返回值,method5无法执行,耦合极为严重。