1. Outline of 6.824:distrubuted system
1.1 Focus: Infrastructure
我们主要关注的是基础设施,而不是构建在基础设施上的应用程序。基础设施一般分为三类:
Storage:存储基础设施。用于实现对海量数据的存储,容错,分片等等。
Computation:计算基础设施,如我们今天讲的MapReduce。
Communication:我们在通信基础设施上会花费更少的时间。可以看mit6.829或cs144。
1.2 Main topics
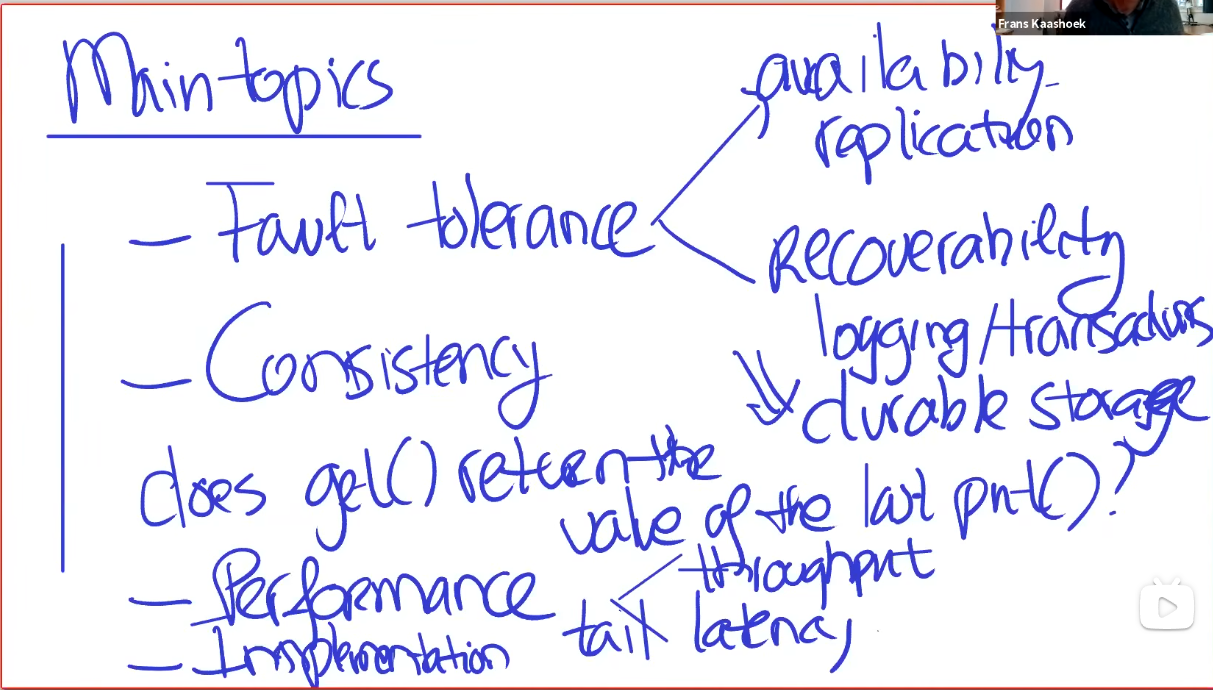
一共4个主要话题。FT、Consistency、Performance是无法完美兼顾的,我们通常会牺牲一些特性来换取另外一些特性,如牺牲一些容错、一些一致性来换取更好的性能。
2. MapReduce
MapReduce中由用户实现的Map或者Reduce函数是函数式的,即我们常说的函数式编程,论文中也提到这些函数最好是确定性的(strong semantics),即对于相同的input,总会生成同一种output。
2.1 Core Workflow
MapReduce中,map函数之间是完全彼此独立的运行的,不用进行通信;Reduce函数也是如此。这依赖于我们对输入数据和从map得到的中间数据分别进行了分区,确保任务之间独立且不会产生额外的通信成本。
Map阶段:输入文件被分割成m个splits,每个split被分配给一个map任务进行处理。每个map任务都会对其分配的split进行处理,并生成一组中间键值对。这些数据被分为R个分区,保存在Map所在机器的本地磁盘中。
Shuffle阶段:在map阶段之后,中间键值对会被划分到r个reduce任务。每个map任务都会为每个reduce任务生成一个分区,并将属于该reduce任务的所有键值对发送到相应的分区。
Reduce阶段:每个reduce任务会从所有的map任务中收集其对应的分区数据。然后,reduce任务会对收集到的所有键值对进行处理,生成最终的输出。如何把输出生成到全局文件系统中,论文中采用的是,先在全局文件系统中创建一个临时文件,将内容不断地写入,当output写完之后,对该文件使用atomic rename操作,将其名字修改为最终的输出文件。
这种设计使得MapReduce能够有效地处理大规模数据集,因为map和reduce任务可以在不同的机器上并行执行,而shuffle阶段则负责在这些任务之间传递数据。
在MapReduce模型中,每个reduce任务需要从所有的map任务中读取其对应的分区数据。这个过程通常被称为shuffle阶段。在shuffle阶段,每个map任务会将其生成的中间键值对按照reduce任务进行划分,master负责将中间数据的所在路径通知到所有reduce机器。因此,每个reduce任务都需要与所有的map任务进行通信,以便从每个map任务中获取其对应的分区数据。这种设计使得MapReduce能够在大规模集群上高效地处理大数据。
注意这个Shuffle阶段是相对昂贵的,shuffle操作是由MapReduce库自动完成的。在MapReduce模型中,开发者只需要关注map函数和reduce函数的实现,而shuffle阶段的数据传输和排序等操作都是由MapReduce库自动处理的。这样设计的目的是让开发者能够专注于处理数据的逻辑,而不需要关心数据的分布和并行计算等底层细节。
2.2 Network Communication
在MapReduce中,网络通信一般会在如下的阶段发生:
- Reduce worker读取中间数据时,需要从Map机器的本地磁盘你中读取。
- 当reduce产生了最终的output file时,如果需要将这个output file从本地传输到全局文件系统中,那么这里也会有一些网络通信。论文中采取的是Reduce函数会在全局文件系统中生成一个临时文件,即一开始就在GFS中,而不是在本地磁盘中先生成,当生成完毕时,Reduce会采用Atomic Rename的方式将该临时文件命名为最终的输出文件。
Map阶段一般没有网络通信,因为Map进程所在的机器一般与他要读取的split所在的机器是同一个,相当于本地读取数据。
2.3 Fault Tolerance
协调器采取的基本策略是重新执行。无论是执行任务的机器崩溃了,还是因为发生了分区导致其无法与coordinator进行通信(但是该机器确实是完成了这个任务),MapReduce解决这种问题的统一办法就是重新执行。所以我们需要考虑Map和Reduce函数是否可以重复的完成两次或是多次。
Map函数可以完成两次吗?
- 可以,因为大多数的Map函数都是确定性的,对于相同的input总是会生成相同的output,都存储在worker的本地机器上,因此无论reduce后续从哪个机器上读取,结果都是正确的。
Reduce函数可以完成两次吗?
- 如2.2所示,因为论文中采取的是atomic rename临时文件的方式,因此Reduce函数不管完成几次,全局文件系统都只会接收第一次完成生成的文件,后面再完成的时候,atomic rename操作就会失败,名称不能重复。
2.4 other failures(在lab中要考虑的问题)
协调器会失败吗?
- 论文中的设计假设协调器基本不会fail,因此如果协调器down掉了,那么整个MapReduce系统都会崩溃,需要完全的重来。论文中没有对协调器做fault tolerance相关处理。
如何应对slower worker?即执行的超出我们预料的map或reduce worker,该如何应对。
- 论文中专门提到了这一块,Backup Task机制那一节。
back.