Certificate Transparency Equivocation
1. The evolution of CT
1.1 background
到目前为止,我们讨论的分布式系统都是一些较为封闭的系统,所有的参与者都值得信赖。这里的封闭的意思是它们都运行在同一个相互信赖的组织下,并不是对所有人都开放的。
但是也有系统是构建在网络环境下的,是对所有人开放的,这种系统中的所有使用者都是互相不信任的,并且通常也不存在那种所有人都普遍信任的机构来运行或保护这种系统。那么我们今天讨论的就是如何在这种互不信任的情况下构建出一个高效的分布式系统。
1.2 Man-in-the-MiddleAttack

在SSL/TLS证书被提出之前,人们对于这种中间人攻击是毫无办法的。以用户访问gmail网站为例,正常情况下,用户在浏览器中输入gmail.com,这个请求会发往DNS服务器,DNS解析该域名后返回给用户对应的IP地址,用户可以访问到gmail的服务器。
图中的方格子就是所谓的中间人,它会在用户向DNS服务器发出解析请求或DNS服务器向用户返回结果时发起拦截,结果就是返回给了用户一个假的gmail的IP地址,但是界面很逼真,用户在假的IP地址上输入账号密码,导致用户的信息被盗取。
1.3 SSL/TLS证书和Certificate Authority
当我们访问https链接时,使用的就是SSL/TLS证书,证书是由证书颁发机构(CA)颁发的。为了解决上述问题,gmail.com域名是使用一个public/private key pair。私钥只有gmail自己知道是什么,并且安全的、容错的保存在gmail的服务器中。
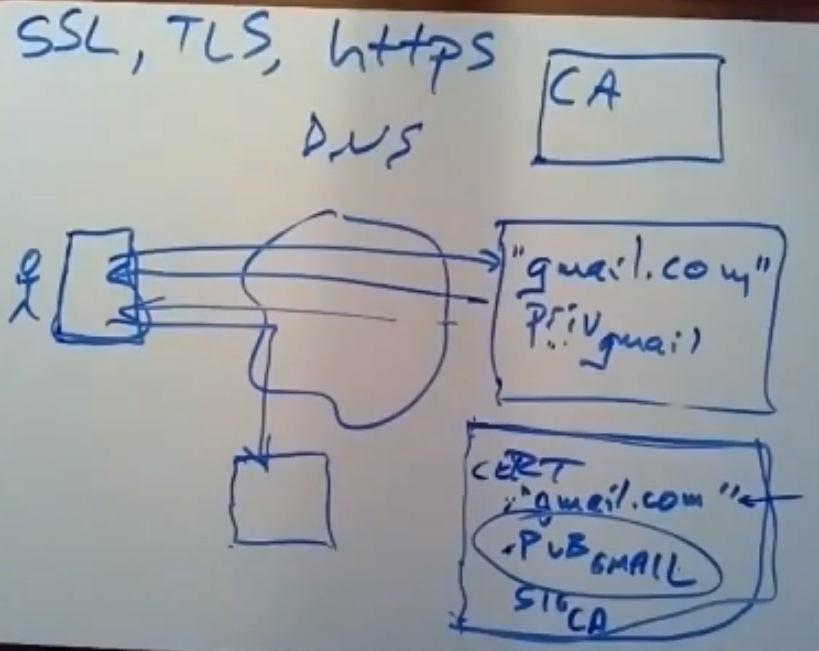
当浏览器要访问Gmail时,它会使用Gmail的公钥去验证Gmail的私钥是否正确。这个过程是通过TLS/SSL协议实现的。TLS/SSL协议是一种安全协议,用于在计算机网络上保护通信安全。
Google在设置Gmail的服务器时,会通过电话或邮件的方式联系CA(certificate authority)。请求CA给自己颁发一张DNS name为gmail.com的证书,CA首先会验证Google是否真的拥有gmail.com这个域名的所有权,当验证通过后,CA会给Google颁发这张证书。
简单来讲,一张证书包含如下内容:
domain_name: gmail.com-要授予的域名
public_key: gmail.com服务器的公钥
signature: 基于CA的private key制作的证书的签名
可以通过检查signature来对该证书进行检查,CA会断言这个public_key确实就是gmail.com的公钥,同时gmail服务器上会保留一份该证书的副本,当有任何人用本机的浏览器通过https连接到gmail.com服务器时,服务器都会首先将这个证书返回给访问者的浏览器,接着,浏览器就会发送⼀个随机数字之类的信息给服务器,并要求服务器通过它上面保存的private key对该数字进行签名,那么该浏览器就可以使用该证书中的public key来检查这串随机数字是否是基于private key进行签名的。
里面存在着某种比对机制,浏览器用公钥对由gmail服务器发来的这条用私钥加密后的信息进行检查。这与证书中的public key有很大的关系。
1.3.1 why this make man-in-the-middle attacks harder?
如上所述,假设我们设置一台与gmail.com很像的流氓服务器,按照上面的中间人攻击的逻辑,用户访问的应该是这台流氓服务器,但是在加入SSL/TLS后,因为流氓服务器上并没有与真正的gmail服务器相同的private key,这是无法通过上述的验证的。
攻击者不能伪造一份与真正的服务器相同的证书,主要有以下几个原因:
- 公钥和私钥:在证书签发的时候,公钥、私钥、签名、摘要等都是根据申请者的域名生成的。如果攻击者试图替换公钥,那么证书就会对不上,也就不会受到浏览器的信任。
- CA机构的角色:证书需要由受信任的证书颁发机构(CA)签发。CA机构在签发证书时会进行身份验证,确保申请者拥有他们声称拥有的域名。如果攻击者试图伪造一个证书,他们需要能够欺骗CA机构,这通常是非常困难的。
- 证书链验证:当客户端收到服务器的证书时,它不仅会检查证书本身,还会检查证书链。证书链是一个由多个证书组成的列表,每个证书都由其上一个证书的私钥签名。这个过程一直回溯到一个受信任的根证书。如果链中的任何一个证书无法验证,整个链就会被认为是无效的3。
因此,虽然理论上攻击者可以尝试伪造一个证书,但在实践中这通常是非常困难的,并且需要克服很多障碍。
1.3.2 Not All CAs can be trusted
世界上现在有上百个证书机构,任何证书机构都能生成证书,网站所有者可以任意更换证书颁发机构。像Chrome、Firefox之类的浏览器内部会放一个保存着几百个证书机构证书的public key列表,浏览器只会认可来自信任列表中的CA颁发的证书。
但是现在问题在于CA本身并不是绝对可靠的,历史上有多次证书机构伪造证书的情况发生,比如说CA将域名是gmail.com的证书颁发给了其他人,但这个证书本身应该颁发给google。无论这种行为是不小心的还是真的出于恶意,这可能会导致证书被滥用,从而使恶意者拥有了窥探用户隐私的可能。
我们无法去让所有的CA机构都变得可靠,世界上之所以有那么多的CA机构,是因为不同国家之间都不是相互信任的,因此他们会使用自己内部的CA,那么我们该如何协调并解决这个问题呢?其中的一种方案是在全球范围内建立一个保存着所有有效证书的在线数据库,每次浏览器访问网站时都需要去这个在线数据库中去验证正确性,但是依然有问题,我们还是不知道谁才是DNS name的真正拥有者。
这种方案理论上可行,但是谁来管理这个全球数据库,没有一个所有人都信任的机构能做到这一点,因为世界上的人都是互相不相信的,他们都有自己的CA,我们无法期望有一个机构能够精准的区分有效和无效证书。
关键点在于,无论证书是有效的还是无效的,他们都是不公开的,仅仅提供给访问该域名的浏览器等等的相关个体,因此这些欺诈证书的案例都是不经意之间被发现的,我们想找到一种方案,可以尽快的发现这些欺诈证书,而不是受害之后、或者是偶然发现这些欺诈证书。
基于这个特点,Certificate Transparency应运而生,CT会迫使任何人(只要是关心这些领域的人)更容易注意到这些伪造的证书。
1.4 Certificate Transparency
简单来说,CT会为我们提供一个可信任的有效证书数据库,以避免证书欺诈,但是其中有很多细节值得探究。
CT本质上是一个审计系统,CT所做的并不是去构建一个防止证书欺诈发生的系统,即CT无法做到防止CA伪造证书,但是CA会启动audit(审核)功能,CT是一个使所有的信息都公开的系统,这样的话,所有关心这些的人就可以对所有签发过的证书进行检查。
这样就修复了之前的问题:证书机构签发伪造的证书,但是没有人会注意到这一点,因为这些证书在之前是不公开的,只有机构和”假的域名所有者”会知道这一点。有了CT LOG系统后,这些伪造证书会更容易被发现,CT具有的一个很强的特点是审计,而不是预防。
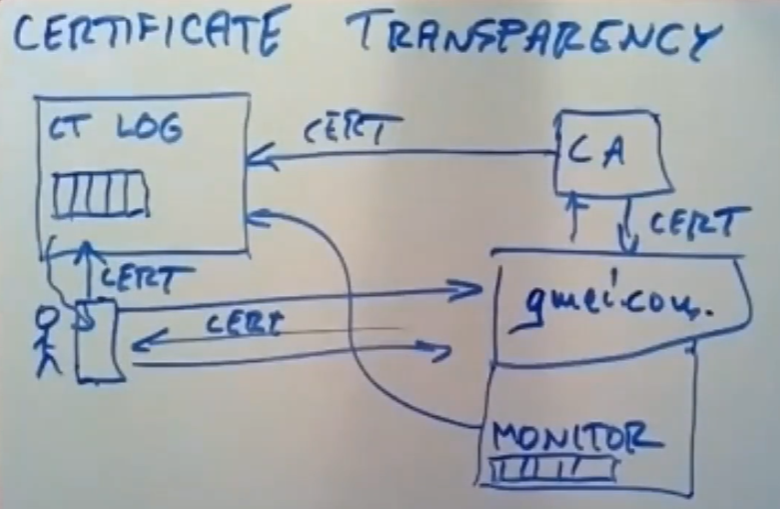
还是gmail为例,如上图所示,当CA签发真正的gmail证书给google时,这份证书不仅会给Google服务器本身,还会发送到一个完全公开的CT log日志服务器中,该CT log服务器中保存了它管辖地区中所有CA签发的所有证书,所以CT服务器中有数百万个证书并不稀奇。
当某个用户用https与Gmail进行通信时,用户浏览器会从gmail服务器处收到它的证书,浏览器会把该证书发往CT log中进行验证,判断该证书是否在CT log中,如果存在,则可以用,否则不用。
但是这个证书依然可能是假的,因为任何CA都可以往这个CT log中插入证书,可能上图的CA是恶意的,gmail服务器并不是真正的gmail.com域名的拥有者,这会诱使用户使用那些伪造的证书。
因此,真正的gmail服务器本身会运行一个用于监视CT的系统-Monito(监视器)系统,基本上大型网站都会有一个对应的Monitor,该Monitor会定期与CT log服务器进行通信,以获取一份它的日志副本,或者有checkpoint机制,只需要获取checkpoint之后的新日志记录副本即可。
所以该监视器会注意到CT log中的每一份证书,因为该监视器是负责监控Gmail.com的真正服务器的,他知道Gmail的正确的证书应该是什么(公钥、签名等等独一无二的信息),如果某些恶意证书机构给Gmail.com这个域名颁发了恶意证书,那么Gmail的监视器就会在例行检查的过程中从证书日志中偶然发现这个伪造证书他就会采取一系列的措施来处理这个恶意证书。
还有一些Moniter-监视器是由CA本身运行的,同理这些CA知道他们颁发过的证书是什么,如果Monitor在CT log中发现了一份不是由自己颁发的证书(域名相同),那么它至少可以提示一下真正的Gmail服务器,告诉他有伪造证书出现。
此外,还有一些第三方的Monitor系统,Gmail等真正的域名拥有者可以将自己的域名与相关的有效证书提供给第三方监视系统,他们同样可以识别伪造证书。所以人多力量大,监视器系统越多越好。但是注意在这个系统中所有的组件都不是百分之百可信的,所以仍然有一定的风险。
1.5 Key Points at CT schemes
在CT生态系统中的任何组件都不是绝对可信的,可能都有恶意,所以这对我们需要构建的日志系统提出了一些要求,可以在拜占庭问题存在的情况下,依然可以确保该日志系统是”诚实的”。
Append-Only:CT log系统必须是仅仅支持append-only的,即他不能前脚让浏览器确定该证书可用,后脚再向对应域名展示证书之前把这个恶意证书删掉。
No Forks:从某种意义上说,我们不希望日志系统保存两份日志,即展示给监视器的是没有恶意证书的,但是展示给服务器的是有恶意证书的。
日志系统在满足以上两点后,它可以防止删除操作,或者说,监视器可以检测出有人执行了删除操作;并且可以避免由于forks操作带来的模棱两可的情况,所以日志服务器只可以拥有一份日志。
所以我们需要Merkle Tree来帮助我们做到这一点。
2. Merkle Tree
2.1 logs structures of CT based on Merkle Tree

一个log服务器可能会保存数百万份日志,所以我们不想让浏览器把整个日志文件都下载下来,这太耗时了,所以我们允许LOG系统将日志的可信摘要或明确摘要的部分发送给浏览器。对此,LOG服务器基于merkle树实现了一种基于Hash值的摘要方法。
基本方案是,log服务器会使用加密hash对上述日志中的记录进行哈希处理,从而最终生成一个加密的hash值:两条记录生成一个hash值,之后向上层递归的生成,最终会生成一个顶部的hash值(Signed Tree Head)。通常加密的hash值是长度为256bit的字符串,顶部的hash值总结了所有日志的内容,而在树的底部,每一条日志记录都会有一个独一无二的对应的加密hash值。
该方案可行的理论基础:对于加密hash方案(如SHA-256这种加密方法)而言,在hash函数中要找到两个不同的且具备相同输出结果(得到的加密hash值)的输入元素是不可行的。因此,这意味着如果log服务器将某一次的STH值发送给监视器或者用户浏览器,对于该值而言,它对应的日志序列是唯一的,无法通过其他日志生成相同的STH-hash值。
实际上,log服务器会拿到树顶部的hash值,之后用自己private key对其进行签名,最后把结果提供给浏览器和监视器;对该值进行签名的意味着,日志服务器(证书机构)以后不能去否认该值,因为这是他们生成的;这样一旦log服务器想修改日志,那么前后的STH-hash值就会发生变化,很容易能找到说谎的log服务器。
所以这种STH-hash值是log服务器的一种承诺,代表了特定的日志序列,根据加密算法特性,它没办法用不同的日志内容序列生成相同的STD-hash值。log服务器用这种方法证明自己的可信性。
日志的增加在之前的材料中也读过,详细细节可以去看那篇文章。
2.2 Proof of inclusion
我们假设浏览器之前拿到的STH值是正确的STH值,log服务器没有使用fork攻击,它只有一份STH-Hash值。
log服务器用于向浏览器或监视器证明log服务器确实包含某一条日志,并给出该日志的具体位置-哪一层的第几个。在原文中,LOG服务器会返回给浏览器一系列的hash值(logN个hash值,N是总日志数量),让用户可以用目标证书的hash值自己去计算中顶层的STH-Hash值,并对比是否与当前log服务器中的目标merkle树的STH-hash值相同。
用户浏览器内部有一个可信任的log服务器的列表,当浏览器发现某个log服务器在同一个Merkle树下某个STH-Hash值不同时,他就认定该log服务器删除了一些日志,因此将这个log服务器从可信任列表移除。
2.3 Fork attack
当然更普遍的是log服务器本身就是不可信的,它可能故意的提供给浏览器一份包含恶意证书的STH值,即Fork行为产生两份日志,正确的那份给监视器看,错误的那份给用户浏览器,从而诱导用户浏览器去访问恶意的IP地址,那么我们该如何处理这种情况。
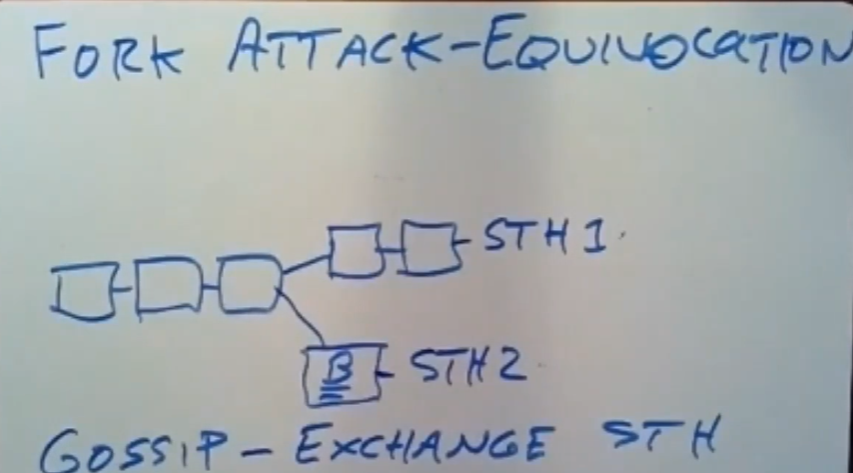
如上图所示,某个恶意的log服务器想要采取欺骗攻击,它在日志的某个时刻进行了fork,因此产生了两个不同的STH值,没有恶意证书的STH1提供给监视器,有恶意证书的STH2提供给客户端。并且这两个分支会往后顺延。
为了解决这个问题,我们需要在监视器与客户端浏览器之前增加一个GOSSIP机制,即监视器和浏览器之间可以互相比较自己在同一个log服务器中拿到的对于同一份日志记录拿到的STH值,当他们发现双方的STH值不相等时,就会发出警报,因为从同一个log服务器上拿到的STH值不相等,这意味着日志被篡改了,或者存在恶意攻击者使用fork攻击,此时浏览器就会拒绝使用这个恶意证书。
具体细节不需要了解,但是这种技术确实可以在一定程度上防止fork攻击。Gossip的具体方案可以看下面的第三部分中的详细说明。
当前并不是所有的监视器和浏览器都支持GOSSIP机制,但是这是一种趋势。
3. Merkle Log Consistency Proof
3.1 Inclusion Proof
比如说,我们要求log服务器能证明H1是H2的日志前缀,或者浏览器要求证明自己拿到的证书确实是在当前的STH值代表的Merkle树中。也可以在一定程度上防止Fork attack。
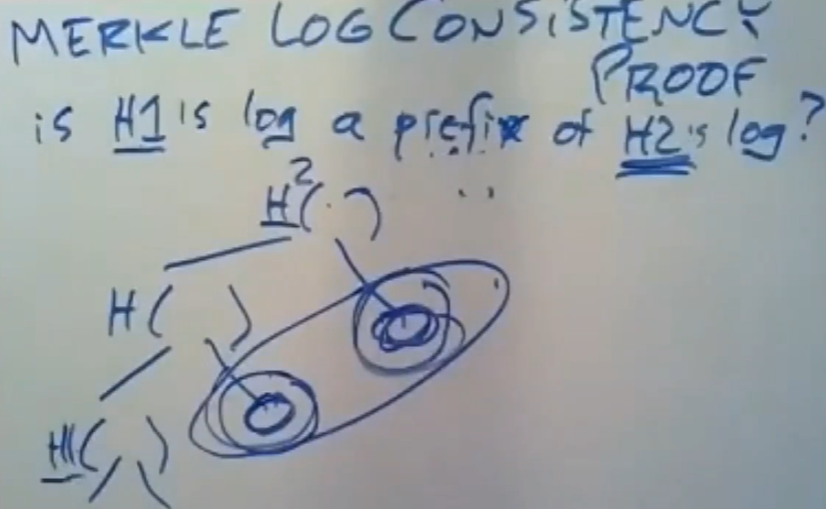
一般由浏览器向日志服务器提出这个要求,之后日志服务器会返回给H1和H2的值,这部分值是之前log服务器签名生成的,无法更改,还有相关的必要HASH值(图中画圈的两个HASH值就是必要的,不难发现我们需要的其他hash值的位置是有一定规律的),我们要用这些hash值计算出目前的顶层STH值(即H2)。
如果H1确实是H2的日志前缀,那么用给定的HASH值计算出来的结果就与H2相同,如果与H2不同,说明日志服务器给了我们一个可能有问题STH证书日志,或者它本身使用了Fork Attack攻击。这个机制会当做上面提到的GOSSIP协议的一部分去使用。
3.2 Browser,Monitor的GOSSIP 机制
上述的Inclusion Proof被当做Gossip的一部分使用,此外,向日志服务器发送证明请求的一般是浏览器或者监视器,但更多是浏览器有这个需求。
GOSSIP协议大体内容如下:浏览器会和某些中央仓库定期通信,并将自己从日志服务器拿到的数据共享给STH pool(中央仓库维护的保存来自各个浏览器、监视器的STH值的缓存数据结构),pool里的内容是多个浏览器或监视器近期在日志服务器中看到的STH值,不同pool之间当然也存在交流,共享自己看到的STH值。
浏览器会定期从pool中取出一些STH值出来,不管取出的是什么,他都会要求日志服务器去生成关于这一对STH值对应的log consistency proof,如果存在欺骗,那么最终会有一个客户端(浏览器或监视器)会拉取到存在欺骗的STH值pair,而日志服务器是无论如何都无法生成Inclusion证明的,因为日志服务器存在Fork attack现象。
因为日志服务器向其中一个客户端展示了伪造的证书,但是对其他的client隐瞒了这件事,但是随着不同pool之间的交流,这种欺骗现象会被很快的发现。
3.3 Client needs Inclusion Proof- Ensure Fork Consistency
不仅GOSSIP协议需要Inclusion Proof,在浏览器执行常规操作时也会用到包含性证明。这可以有效的保证浏览器看到的日志内容始终都是连续的(即如果LOG服务器发生了Fork行为,那么这可以确保浏览器始终只会看到一个分支上的内容,而不会中途发生分支切换,我们称这种保证为Fork Consistency)。
log服务器想要让client切换分支是不可能的,因为不同分支无法生成Inclusion Proof,只有在同一个分支上的STH值才可以生成包含性证明,因此收到恶意证书的服务器会在这个包含恶意证书的分支上越走越远。
当后续该client参与GOSSIP时,就会把自己所在的恶意分支的STH值放到STH POOL中,这样很快就会有client发现该日志服务器发生了Fork行为,有恶意信息的出现。
3.4 Fork Consistency + Gossip
综上所述,Fork Consistency + Gossip可以确保所有的参与者(浏览器,监视器)看到的都是相同的日志,即任意两个不同时刻的STH值(后生成的STH值一定包含了前面的STH值)都可以生成包含性证明。如果有client被颁发了恶意证书,那么它就会看到和别的client不同的日志,看到不同的STH值,这总能被检测出来,原因如下:
- 如果日志服务器没有针对该恶意证书做出fork行为,说明日志服务器本身就是恶意的,这份恶意证书很快就会被真正持有该证书的正确版本的Monitor发现,因为Monitor会定期检查log服务器的日志。
- 该日志服务器很聪明,为了躲避监视器的追查,它采取了Fork攻击,将恶意证书保存到一个分支上-STH2,将恶意证书的正常版本保存到另一个分支上-STH1,将带有恶意证书的STH2给特定client看,将另一个分支给别的浏览器和监视器看。由于gossip机制的存在,总有一刻会有别的client看到这个恶意证书的分支的STH值,但是这个值是无法和正常分支上的任何STH生成inclusion proof证明的,因此会发现这个问题。
4. some tips about CT System
4.1 multi log servers,the trusted standard
CT系统中通常会使用多个log服务器,以防止某个log服务器变得恶意或出现故障等等。但是查到这些故障需要一些时间,因此在这些寻找的时间里,可能还是会有client使用那些恶意的证书,所以这个系统只能在一定程度上减少恶意证书带来的影响,并不能彻底杜绝这个问题,即一般情况下我们无法立即发现这个问题,这需要一定的时间。
不同日志服务器间的日志不必相同,因为他们可能保存了不同的CA颁发的证书,对于某个证书而言,只要该证书至少在一个日志中,并且所有人都知道该日志是可信的就可以了。关键在于该日志服务器本身并不存在fork行为,只要不存在fork行为,就足以证明该log服务器本身是可信的,但是无法证明证书本身是可信的,这需要正版证书对应的Monitor来审计。
所以log服务器的可信判断与证书本身是否可信的判断是不一样的,是否存在fork行为用于判断log服务器本身是否可信,证书本身的可信度则要靠正版证书的Monitor;当然如果出现了Fork行为,就需要依赖我们上面谈到的机制了。监视器会去查看浏览器愿意接受的所有日志服务器。
4.2 If log server crashes
浏览器厂商可以决定哪些日志服务器是可以信赖的,哪些是恶意的或者不能使用的,因此当日志服务器崩溃,从而没有回复我们发送的请求的Inclusion Proof时,我们需要判断日志服务器为什么没有回复,是因为它本身存在了fork行为无法回复,还是说单纯的因为故障恢复后在恢复原有的日志。
这需要Monitor和浏览器厂商具有足够强大的审计能力。
5. Summarys
CT中一个极为重要的特性是,在一个区域内,对于一个log server而言,他服务的所有群体(CA、浏览器、某些域名服务器的监视器)看到的都是相同的日志内容。如果有人看到不同的,那么我们迟早可以检测出来。
只要存在伪造证书,监视器迟早可以检测出来,如果监视器发现了伪造证书,那么就可以就可以把这些伪造证书放入吊销系统,在之后该证书就会被禁用,这种机制很久以前就已经存在了。
此外,我们学到的另一件事情是,如果我们在设计系统的过程中,没办法找到一种防止不良行为的方式,那么我们可以去构建出那些依赖于审计这些行为而不是防止这些行为的工具,我们可以通过检测的方式检测出这些行为。这通常要比阻止不好的事情发生来说要更为简单一些。
还有一旦某个恶意log服务器对某个client进行了fork attack,那么Merkle的Inclusion Proof特性就会强制用户呆在这个恶意分支上,因此恶意log服务器无法删除某个分支来销毁证据,一旦删除后,client那边无法通过inclusion proof,就会判定该log服务器是恶意的。如果不删除,那么通过gossip机制,也可以很快的检测出log服务器存在fork行为,总之我们需要一种通信方式可以让不同的参与者进行通信,这样他们就可以比较各自的STH情况,从而判断出该log服务器是否存在fork行为。
back.