COPS,casual+ consistency
1. Eventual Consistency
1.1 Intro
前面学习的Spanner、memcache,从clinet的角度而言,虽然read都是在本地执行的,但是write操作必须发送给primary节点(region),写操作的速度是一个限制。
而COPS让客户端可以在本地的集群(region)中进行read和write操作,而不需要同步的(实时的)将这一次的写操作发送到别的数据中心中,即client不需要收到别的DC中的回复。分布式中,一致性与性能一直是两个不能兼顾的点,这里我们优先考虑性能。
在讨论COPS之前,会先讨论两种还算不错,但是不能说好的设计方案。(从客户端的角度来看,这些方案都可以满足local read、local write),但是写操作有所不同,分片服务器需要记录每一步写操作,并将其发送到别的DC中。我们称这些方案为StrawMan1和StrawMan2。
1.2 StrawMan1-Eventually Consistency
每个DC内部有着若干DB服务器,将数据进行分片存储到不同的server上。
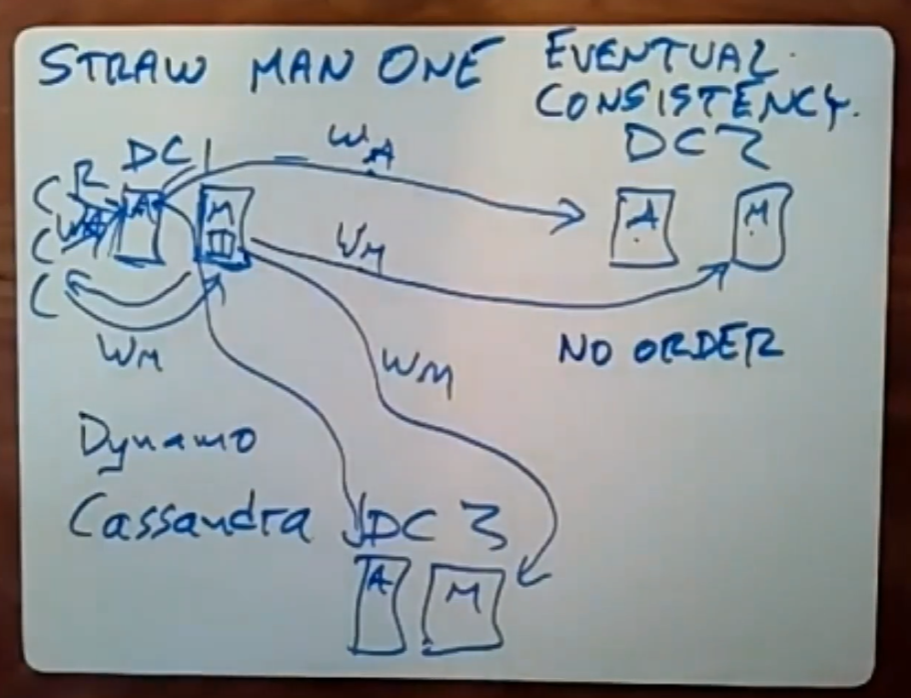
1.2.1 Main-Read Scheme
读取操作在本地执行,服务器会返回对应的值。
写操作也是在本地执行,当服务器收到并执行了写操作后,会向client回复一个完成的消息;但是注意,每个服务器还会维护一个队列,这个队列记录了该服务器从client那里收到的write操作;服务器会在后台以异步的方式将队列里的、且已经在本地执行完的write操作发送给其他DC中对应的分片服务器。
由于涉及到网络I/O,所以要花费大量的时间,不同的server各自维护自己的write操作队列,因此服务器执行write操作与发送write操作(一般必须是服务器已经执行完的)到别的DC中的服务器,这两个操作是并发的。
这种设计偏向于读操作,但是写操作时要多花费一些性能。
1.2.2 Main-Write Scheme
如果我们更在意写操作的性能,则可以采用这种方案:读操作时,需要从多个DC中获取数据,写操作则只需要纯粹在本地执行。
读操作实际上需要从其他DC中获取到该键所有的相关数据,从中选出版本号最新的那个。写操作则本地写即可。
1.2.3 Read And Write-Quorum Overlap(More Common)
如果我们对读写操作的性能都很在意,那么可以把上述的两种方案进行一个折中:
执行写操作时,要把这个写操作发给多数DC执行,并且他们都执行成功即可。
执行读操作时,从多数DC中获取到这个键的数据,取最高的版本。
这实际上依赖于重叠的那部分服务器,所以我们一般总是能获取到最新的数据。
这种方案被很多工业级系统采用,如Amazon的Dynamo和开源的Cassandra系统,虽然在一些细节上有所区别,但是他们遵循的基本模式是相同的,这种方案就是最终一致性(Eventual Consistency)。
最终一致性意味着,当人们不再进行数据更新与写入时,且所有的写操作消息都最终到达了位置且被处理,那么最终一致性系统中所有replica保存的值最终都会相同。
这意味着,我们不保证任何顺序,如操作之间的因果关系(因果一致性)、每个键的先后执行顺序(每键一致性),这些都无法保证,但是随着时间的推进,总有一天会得到一个一致性数据视图(key在所有副本上对应的值都相同)。
在单个replica中做到linearizable是容易的,但是一旦有多个DC,那么就会变得棘手。从操作发生的DC中读取数据也许是正常的,但是一旦有别的用户要从别的DC中想要读取这一次的更新,那么在最终一致性下,无法确保能读取到正确的数据(如论文中的相册、相片、相片引用的例子)。
这不是一种错误,这是因为我们采用的一致性标准无法确保能读取到正确的数据。这种情况下需要等一会再去读取,但是这依然不能保证能获取到正确的数据。quorum+gossip的思想就与这个十分的相似。
1.3 Eventual Consistency-Photo App

这个就是论文中的photo例子:用户C1先上传一张照片,之后将这张照片的引用加入到list相册。
位于另一个DC的C2想要去读取整个照片,它先获取到这个相册,之后从相册找到对应的引用,根据引用获取相片的具体内容;C2可能会遇到各种奇奇怪怪的情况。
- 根据引用读取相片时发现相片根本不存在。
- 发现不存在这个相片引用。
这一切都是因为,当C1执行完这些操作后,将这些操作发送往别的DC中时,我们无法确保这些操作到达的顺序,以及这些操作何时到达,我们只知道这些操作最后会到达,所以去读取时会遇到各种异常的情况,所以存储系统的异常行为通常是不确定的,尤其是大量读操作出现时。
1.4 Eventual Consistency-TimeStamp
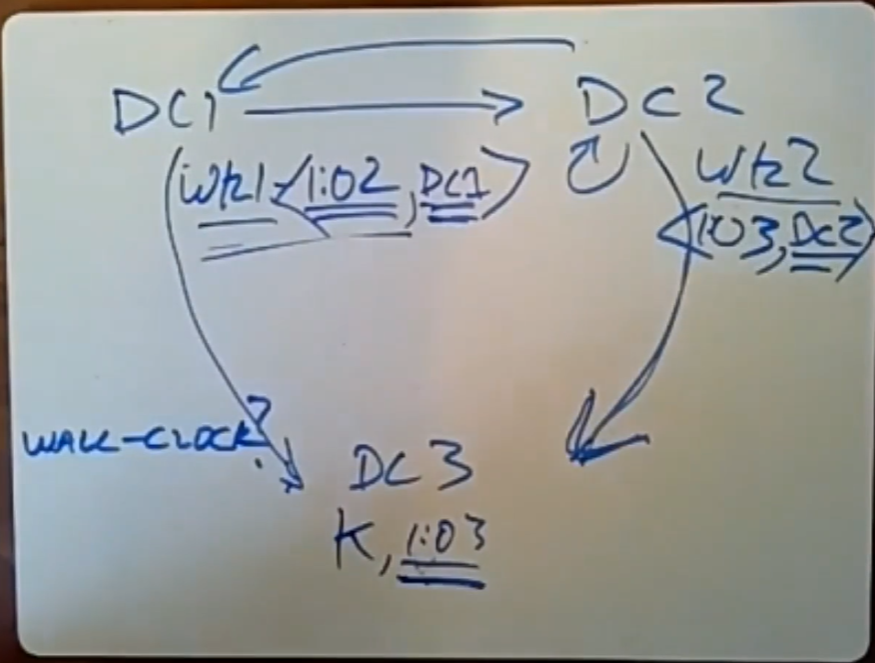
如上图所示,DC1和DC2中都有对某个key的写入,同样写完后需要将这些key传播到其他的DC中,我们至少需要在这些DC之间达成一个共识,即最终(未来的某一刻之后)该key对应的值应该是相同的。因此我们需要用到版本号的概念,最终保存的结果一定是版本号最高的值。
如果两个DC在同一时间对某个key写入,那么他们的时间戳就是相同的,因此需要一种方法来消除歧义,论文中节点将版本号的高位设置为其 Lamport 时钟,低位设置为其唯一节点标识符,这样就可以消除歧义。
此外,如果所有DC上的时间都是完全同步的,那么这个系统运行起来就没问题,但是我们知道不同DC里的服务器、甚至是同一个DC中的服务器之间的时钟都不可能完全同步:比如,DC2的时钟比DC1快5min(假设DC1的时间才是符合真正的时钟的),那么上图中虽然DC2的时间戳大于DC1,但是从真正的时间上看,当DC2的时钟同步过后,应该是DC1的时间戳大于DC2。
在所有DC的全局时钟不同步的情况下,时间戳是没有意义的,因为没有一个参考标准。为了解决这个问题,COPS采用了Lamport时钟来分配时间戳。
1.5 Lamport Clocks

Lamport时钟是一种基于现实时间用来分配时间戳的方式,主要用来解决某些服务器上的时钟跑的太快所产生的的问题。每个服务器会保存一个叫做Tmax的值,它是每个服务器目前从所有地方所看到的那个最高的版本号。
如果某个服务器所生成的时间戳大于现实时间,其他服务器就会看到这个时间戳,它们就会通过这个Tmax反映出这个大于现实时间的时间戳,接着,当一个服务器需要为一个新的put操作分配一个时间戳作为它的版本号时,它会使用这个公式:max(Tmax+1, real time)来计算时间戳。
这就是我们最终一致性系统中分配给这个put操作的版本号值,这就确保了每个新版本号都会比它之前所看到的最高版本号要来得高。如果所有server的时钟正常,那么Tmax+1就会比real time更小;如果某个server上的时钟走的特别快,那么就会参照Tmax+1这个时间戳。
1.6 Conflicting Writes

对于并发写操作,简单地采取保留最高时间戳的方案并不是总是可行的。论文中COPS采用了last-writer-wins的策略(通过比较版本号来确定“最后”的写入),假设如下场景:顾客打开两个页面进行购物,同时往购物车中添加商品,这里就很像上图中的场景,不同的DC中进行并发写操作,我们想看到的是这两个操作都被计入了,而不是只让最后一个写入者胜出。
同时COPS也提到了可以自定义冲突处理程序:如这里应该取两个操作结果的并集。在最终一致性的系统中,这是一个很难处理的问题。
1.7 StrawMan2-Eventual+Sync Barriers
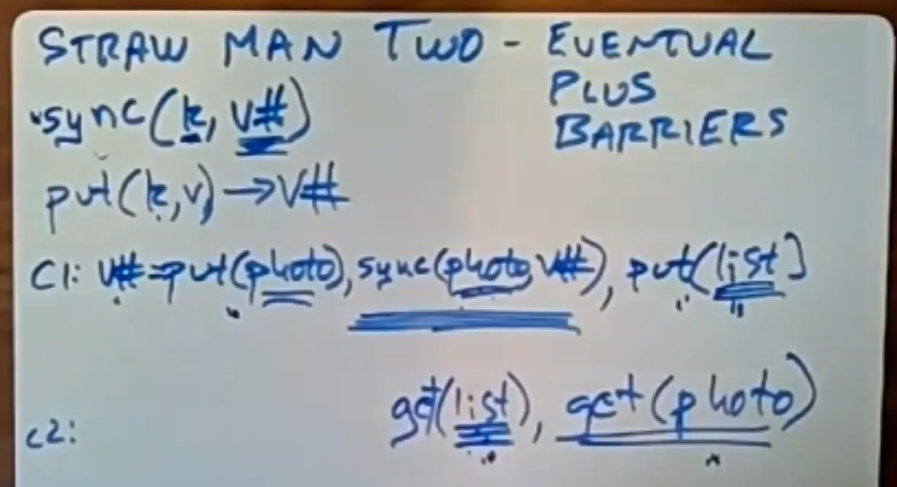
除了Put和Get操作外,client还可以执行一种名为Sync(key,v#)的操作,注意V是值,V#是版本号。
当client调用sync时,sync会一直等待,直到所有的DC中key的副本的版本号都至少和指定的V#相同(大于等于)时,client才可以继续执行下一个操作。
Sync是一种强制指定执行顺序的方式,为了支持sync操作,故put操作必须返回写入后的值的版本号,之后sync可以用这个版本号等待所有的DC都完成这个数据的同步,在这里Sync扮演了一个屏障的角色。注意Sync调用的执行速度很慢,除了需要等待别的DC完成,还得成功收到他们的成功回复。
因此在这里,C1在执行了put操作后,会调用sync操作等待,直到所有的DC都存入了这张照片后,它才会把照片的引用放入到相册中。因此,当C2在别的DC中从相册中得到这张照片的引用时,是一定能够得到这张照片的内容的,因为Sync操作确保了这一点。
1.7.1 Fault-Tolerance
为了防止有某些DC故障而导致Sync操作进入无限的等待,这里采用的方案是Sync操作只需要等待大多数的数据中心完成写入即可,即采取1.2.3中的方案,只要能读取到读、写集合重合的那部分即可。
1.8 Logging-Scheme
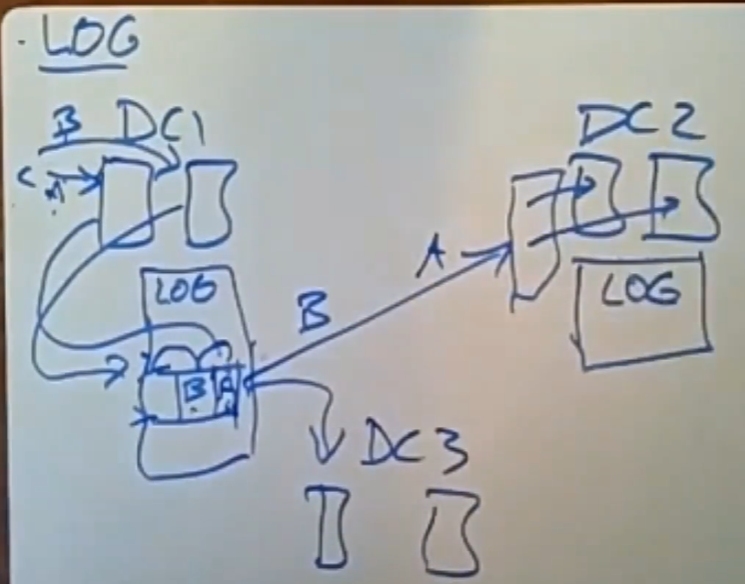
论文中提到采用Log的方案来确保两个写操作的执行顺序,即所有操作即日志,每个DC中配置一个专门的LOG服务器,DC中所有的写操作产生的日志会被发送到这个LOG 服务器中,之后由LOG服务器将日志到别的DC的LOG服务器。通过日志序列号的大小来强制确保操作的执行顺序。这要比上面的sync操作要更快一些。
但是当一个DC中的服务器变多时,LOG服务器的负载就会变得特别大,它异步发送日志的速率就会大大减慢。因此我们想通过某种方式将指向顺序的相关信息传给其他DC,而不是都交给单个日志服务器来进行处理。
2.COPS-Casual Consistency
2.1 COPS(non-GT)

COPS中对于每个client都有一个context的概念,如上图所示,对于Get操作,client只是将这些Get操作的信息放入到自己的上下文中,当遇到第一个put操作时,上述所有的Get操作的信息都是它的依赖,当put操作存储完这些依赖信息后,client就可以清除掉之前的put相关信息。
之后又来一个put操作,它的依赖应该是上面的所有操作:上一次的put与更早之前的get。但是对于NON-GT的COPS而言,我们只需要保存nearest deps信息,即第二个put操作的依赖只需要保存第一个put即可,之前的get操作是一定会被满足的。对于非事务性的COPS而言,只用nearest deps已经可以确保数据的正确性。
这些deps信息的作用就相当于上面strawman2中的sync操作做的事情。在发送时,该COPS shard server会把put操作和它完整的依赖(如put(Q,-)那一堆内容)发送给其他所有DC。但是对于该shard server本身,至少在NON-GT的COPS系统中,他不会存储完整的deps信息,而是只存储nearest deps。
上例中Put(Q,-)的
nearest deps=[z<>v3],完整依赖是deps=[z<>v3,x<>v2,y<>v4]。最左边的依赖是最晚8出现的,越往右出现的时间越早。
对于第一个put操作,只有Z所在的服务器检查到它所携带的依赖信息都被满足之后(检查保存X与Y的服务器上且对外可见的数据版本是否是满足依赖的-可见数据的版本号大于等于依赖的版本号),这个put操作才可以被成功的写入,成功的写入也意味着对DC中的其他服务器可见。
此规则适用于client操作的DC,同样适用于收到这个put操作+依赖的其他DC。
2.1.1 cascade latency
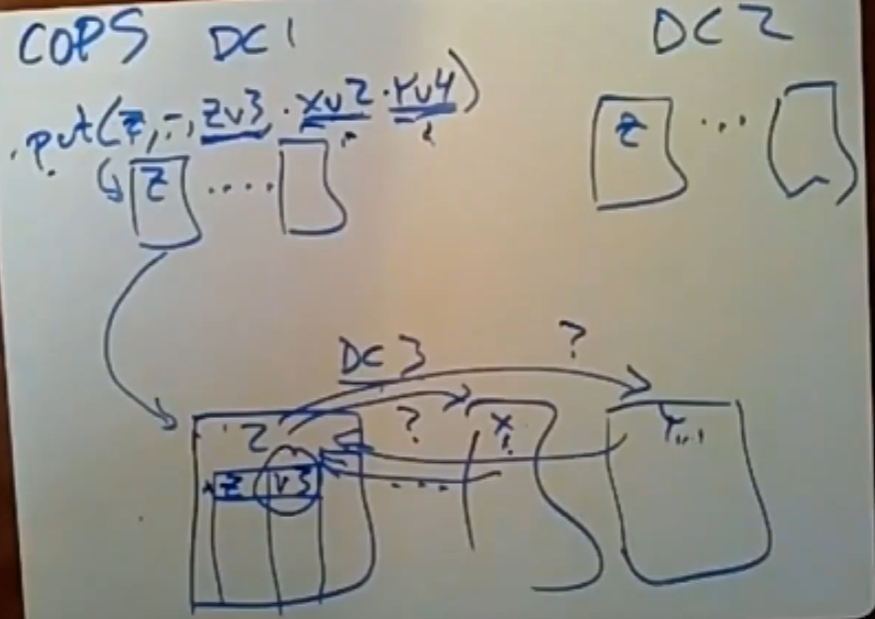
如上述,put需要等待deps满足后才能写入,但如果由于网络故障,Z所在的server永远收不到X的v2版本被成功写入信息,且x的v2要进行写入的依赖也没有被满足,这就会造成级联等待的情况:Z等x_v2,x_v2等自己的deps,这很糟糕。COPS的作者后续有论文专门说明了如何缓解这种cascade latency的问题,感兴趣可以看一下。
2.2 The causal consistency of cops
在同一个上下文中,执行先后的操作存在因果关系,COPS是可以保证这个顺序的,但是不同客户端的操作则需要应用程序去判断他们是否具有因果关系,因此COPS系统不保证不同客户端的操作顺序符合全局时钟。如论文中提到的相册和访问控制权限的例子,我们可能会拿到不匹配的相册内容和访问控制权限。
我们必须明白,从广义层面来讲,因果关系是以COPS无法注意到的方式进行传播的。对于不同client的操作,只有当COPS知道了足够多的信息后(deps足够),这些信息足以让COPS确定不同client的操作有因果关系,COPS才会去确保不同client之间应该存在的某种顺序。
所以我们会看到,即有人相信某个值已经被更新过了,但他们还没有看到更新后的值,因为应用程序并没有给COPS足够的信息让它知道这两个操作有因果关系(位于不同的上下文之中)。COPS只会保证数据在满足现有的deps的情况下被写入,但不同上下文的操作之间的本该存在的因果关系是难以让COPS确定的,COPS需要一些额外的信息去确定这些因果关系。
注意因果一致性与全局时钟没有关系,因果一致性无法确保全局时钟的顺序,通俗来说,同一个上下文先后执行的操作是一定有因果顺序的,COPS可以确保;但是不同的上下文之间的因果关系,则需要通过完整的deps去判断,若deps不足以确定他们之间存在因果关系,那么,COPS-GT不会去确保他们之间的顺序。
2.3 COPS-GT
因此有了COPS-GT去确保这一点,COPS-GT保存了完整的deps信息,因此它可以在不同的client之间的操作中确定一些因果关系,从而使COPS-GT拿到的相册和访问控制权限列表是处于一致的状态的。但是不存在因果关系的操作(一般是位于不同的上下文中且deps信息不足以做这些),COPS是不会保证其执行顺序的。
3. Conclusion
在工业界中,我们很少见到已部署的系统使用因果一致性,有如下几点原因:
- COPS(-GT)只提供了一定程度上的因果一致性关系,它只保证他能看到的(deps信息足够的)。
- 跟踪每个client的因果关系可能会很尴尬,在现实世界中,一个用户的浏览器可能会在不同的时间点和不同的web服务器进行通信,这意味着,只通过单个web服务器去保存用户的上下文是不够的,当用户在访问同一网站的不同web服务器时,我们需要某种方式将单个用户的上下文缝合在一起,这很痛苦。
- COPS只会去跟踪它所知道的因果依赖,这意味着它并没有一种固定的解决方案。或者说,它并不提供一种确定的的因果关系。
- 最终一致性系统和因果一致性系统对事务的支持非常有限,大多数人们希望自己的存储系统能支持事务。
- 用来推送、跟踪以及存储这些依赖信息所需要的开销是非常明显的,如果想做到每秒能处理数百万个操作的那种级别的性能,那么这种开销很可能会是巨大的阻碍。使用因果一致性所产生的开销对于性能方面的影响非常显著。
这些就是为什么因果一致性目前还未流行的原因,但总有一天它会流行起来的。
从下节课开始讲区块链。
back.