1.Spark
1.1 Why Spark
本质上来讲,Spark是MapReduce的后继产物,我们可以认为Spark是MapReduce的进化版本,Spark被广泛应用于数据中心的计算任务之中。
我们主要关于Spark中的这么一件事情:Spark对MapReduce中的两个计算的阶段进行了总结,它将MapReduce总结为一个多步骤数据流图(Multi-Step data flow graph)的概念-即论文中提到的lineage图。
这种模型更具表达力;
在应对优化以及故障处理方面,Spark也有了更多解决的思路;
在遍历数据这块,Spark要比MapReduce做得更好,它可以更方便的把多个MapReduce程序整合在一起,让他们一个接一个运行。
并且对于程序员而言,这也很方便,它支持对应用程序进行迭代。
1.2 Example(PageRank)
PageRank的输入以行为单位,每行有两个URL:<From Url, To Url>,即这意味着第一个url所代表的页面上有第二个url,我们可以点击它跳转到第二个URL所代表的页面。

如上图所示的输入数据,有5个url对,可以根据输入数据绘制出对应的有向图,例如第一个<u1,u3>代表了u1->u3,即从u1的页面上点击链接可以跳转到u3。PageRank会根据其他重要页面是否有指向给定页面的链接来估算给定页面的重要性,即是否能够从from url跳转到to url,他会实时的更新to url的rank值,这些rank值反映了to url被用户访问的频数,从而反映了这个url本身的重要性。
PageRank算法会反复模拟用户查看网页并按照链接跳转的行为,以此提高目标页面的重要性,这些rank值最终会收敛于某个真实的值。
1.2.1 用MapReduce?
你也可以在MapReduce中编写这样的代码,我们不可能通过单个MapReduce程序做到这些事情(即只调用一次是不可能完成的),需要对MapReduce应用程序进行多次调用。每次调用都好似遍历时的其中一步(比如对集合{a,b,c}遍历,单个 MapReduce的调用就好比是遍历到a这一步所包含的操作)。
虽然可以通过MapReduce来做到这点,但是极其耗费资源,而且速度很慢:它只考虑一个Map和一个Reduce操作,它总是从磁盘上的GFS文件系统中读取它的输入元素(磁盘I/O),并且它会将更新后的每个PageRank值写入到GFS的文件中(磁盘I/O),如果使用多个MapReduce程序来做的话,那就会产生大量的文件I/O。
1.2.2 用Spark
这里以用Spark实现的PageRank代码作为样例来讲解,相比于论文中的PageRank代码有了更多的细节,这里我们不关注PageRank算法本身是怎样的,我们关注spark实现的程序做了什么。
再次注意,transformations是定义新RDD的惰性操作(即生成对应的lineage图,另一种理解方式是生成计算方案,而并不会真的去执行计算),而actions会实际意义上的启动计算,根据之前生成的llineage图去执行操作,将值返回给程序或将数据写入外部存储。

// 生成lineage图:该图记录了如何并行读取分布式文件系统中的文件内容
val lines = spark.read.textFile("in").rdd
// 生成lineage图:如何将读到的内容lines格式化,生成一个个的pair<From URL, To URL>。
val links1 = lines.map{ s =>
val parts = s.split("\\s+")
(parts(0),parts(1))
}
// 生成lineage图:记录各个worker如何去掉重复的pairs,即相同的pairs只记录一次,因为是分区的,同样多个worker可以做到并行处理,因为原始的数据分区可以确保相同的记录不会出现在不同的分区,所以各个worker之间的数据都是完全不同的,不用担心数据重合
val links2 = links1.distinct()
// 生成lineage图:将一个给定页面上所有的链接都放在一个地方,groupByKey会根据URL pair中的from URL来对所有记录进行分组;最后得到的就是<url,(the links at the page(url points))>
val links3 = links2.groupByKey()
// 告诉spark,我们想把links3的内容持久化到cache中,因为后续还要重复使用他们
// 有点类似于论文中的persist()调用
val links4 = links3.cache()
// 将每个url对应page的rank值初始化为1
var ranks = links4.mapValues(v =>1.0)
// 模拟用户点击行为,每一次迭代都会更新一次每个URL指向的page的pagerank值
for (i <- 1 to 10){
// 将links和ranks以from url作为join key,将他们连接在一起,最后的结果就是
// jj中包含了每个page的pagerank值以及该page上的links列表
val jj = links4.join(ranks)
// 更新每个page的PageRank值,公式:rank/urls.size
// 每个page的当前rank值/该page上的urls的数量
// 这一步的结果是<FromUrl, PageRank值>,可能会有相同Fromurl的pair出现
val contribs = jj.values.flatMap{
case (urls,rank) =>
urls.map(url =>(url,rank / urls.size))
}
// 先将相同fromurl的记录放在一起,然后合并计算总的rank值
// 注意这里我们假设用户有0.85的概率从当前页面访问url,有0.15的概率直接换一个页面
ranks = contribs.reduceByKey(_ + _).mapValues(0.15 + 0.85*_)
}
val output = ranks.collect()
output.foreach(tup => println(s"$ {tup._1} has rank: $ {tup._2} ."))
val lines = spark.read.textFile("in").rdd:这行代码意味着,我们让Spark去读取输入文件,当Spark读取一个文件时,它实际所做的事情就是从GFS这样的分布式文件系统(别的也可能)中读取一个文件;由于这个大型文件是分片的(一般分布式文件系统都会针对大文件做分片),所以Spark会让很多台机器参与计算,并行读取文件的不同的分区。同样的,这一步操作只是生成了对应的lineage图,并不会真正的去执行操作。
当我们调用Lines.collect()操作时,这意味着我们想看到上一步操作的执行结果:它会让Spark对这个lineage graph进行处理并生成Java字节码,用来描述所有不同的Transformation;它会去让一组worker来处理该输入数据的不同分区,它会将这些字节码发送给Spark所选择的所有worker机器上,这些worker机器就会去执行这些字节码,这些字节码会告诉每个worker去读取它所负责的那个分区输入数据。
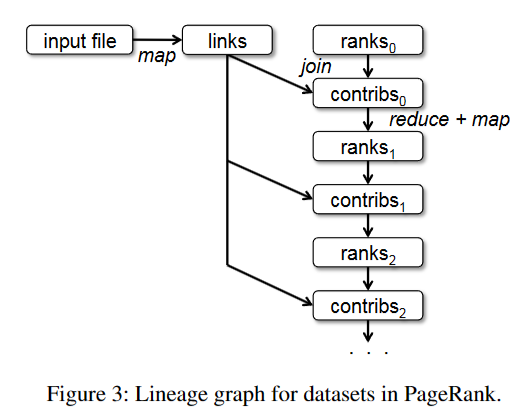
剩下的操作同理,在我们调用Action类操作之前,Spark是不会去真正的执行这些语句的,它所做的只是在lineage图上面(有向无环图)增加新的transformation类信息节点。上图就是对应的lineage图。
主要需要解释的就是links每次的参与,links参与了每次生成contribs的过程,所以我们选择将links持久化到内存中(生成不可变的RDD file),以供我们每次使用。图中并没有写出所有的函数调用,是一个简略过程。
1.3 Execution Model of spark
只涉及到单个机器上的数据的操作是narrow transformation,涉及到多个机器的就是wide transformation。
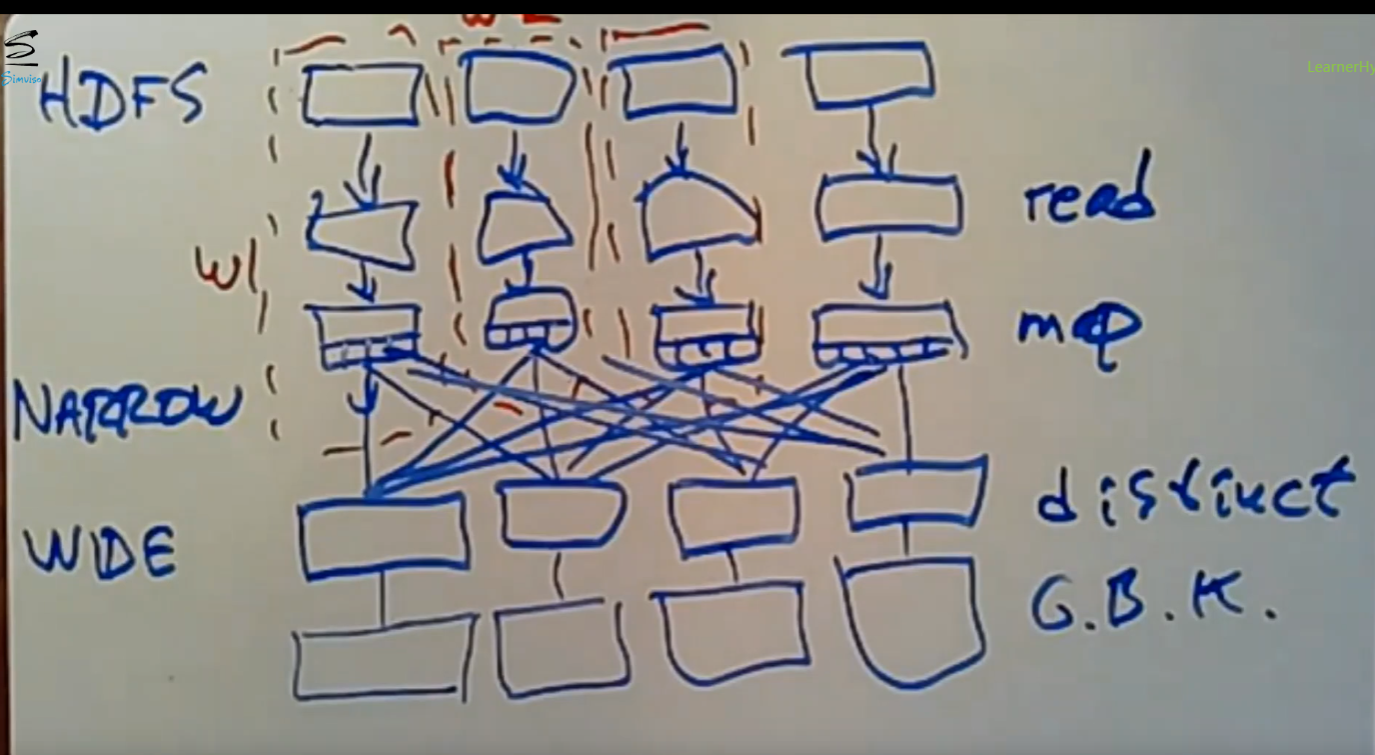
分布式文件系统(如HDFS)提前将数据进行分片,之后Spark只需要给不同的分区分配各自的worker即可,后续处理的时候这些worker完全独立(由于分片是按照分布式文件系统的规则进行分区的,并非严格按照from url,所以仍然可能会有相同的fromurl的数据分布在不同的分片上)。但是在narrow transformation阶段每个worker只需要处理自己机器上的分片即可,故当前不需要网络I/O,
这样worker和自己要处理的分片在同一台机器上,实现了本地化处理,所以无需网络通信。可能后续的distinct操作需要一些机器间的数据移动,这里会涉及到一些网络I/O。像map、join等等这些只涉及本地分片的数据操作是narrow transformation操作。接下来就该涉及到网络I/O的wide transformation操作。
distinct、GroupBy操作是wide transformation操作。是distinct(论文中提到的shuffle)操作,不同worker可能要访问所有的分片去确认是否有重复数据,并最终生成去重过后的数据;之后每个分片会根据key对去重后的数据再次进行shuffle操作(即GroupBy操作),目的是将相同key的pairs数据放到一台机器中,所以这里可能有网络I/O。
wide类型操作涉及到网络I/O,故成本很高。
2. Fault-Tolerance of Spark
由于数据的源头是来自分布式文件系统 ,而分布式文件系统本身对数据有做复制容错,而RDD本身是生成后就不可以修改的,所以每当一个worker故障后,我们只是简单地丢弃这个worker以及所有相关结果,之后让一个新的worker根据生成的lineage图重新执行故障的worker的原来负责的任务即可。
对于narrow dependence的数据而言,需要单独分配一个worker让他重新根据lineage执行;而对于wide dependence的数据而言,只需要把原来worker负责的机器上的分片数据分配到别的存活的worker上即可。
2.1 Failed Worker-Wide Dependency
但是如果涉及到wide transformation数据的worker发生了故障,处理起来就会很麻烦:
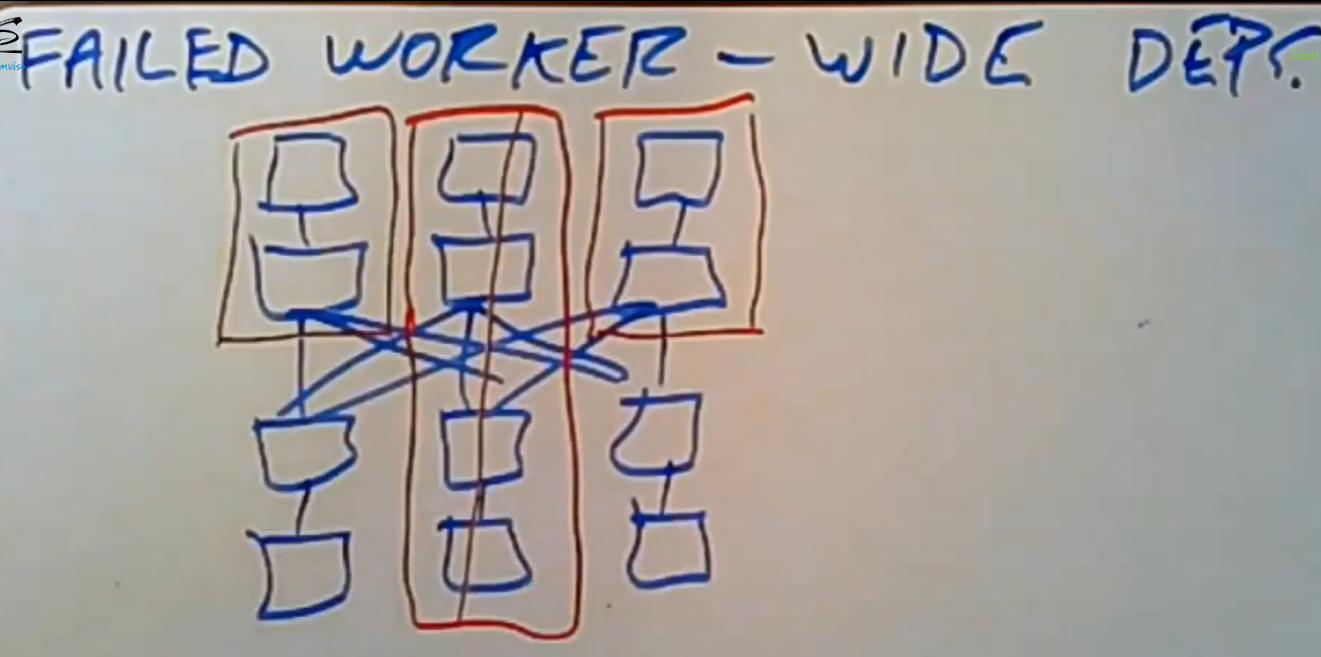
在我们没有显式的调用cache()或persist()操作的情况下,spark是不会把中间阶段的数据持久化到内存中的。如上图所示,中间的worker在最后一步故障了,所以我们需要重新执行这个操作,为了中间的那一步wide transformation操作,由于另外两个worker并没有持久化narrow transformation执行结果的数据,故我们需要让剩下的两个worker重新执行自己的narrow transformation的collect操作,在大数据量的情况下,这尤其的浪费时间和资源。
故Spark允许程序定期的对worker的转换结果进行checkpoint操作。在此例中,Spark将另外两个worker的narrow操作的结果做checkpoint操作(持久化到HDFS存储系统中),这样当再次要用到那份数据时,直接从分布式文件系统中读取即可,而不需要读取原始数据+执行一系列的narrow transformation。
重点在于不需要从头开始对执行中的数据进行备份,不需要重新执行整个计算过程,checkpoint的作用在于此。
Spark的RDD不可变性(每一步transformation生成的数据都是不可修改的)是这些策略的基础。
3. Conclusion
Spark适用于对海量数据进行批处理(coarse-grained),但是不适用于细粒度的数据处理。
Spark本身不适用于对数据流进行处理,即必须事先给出所有的可处理的数据,故不支持流式处理(这里的流式处理可以类比一下DB中的operator的inter-operator处理模型)。但是Spark Streaming模型适合流式处理。
Spark是一种升级版的MapReduce,解决了MR中的一些性能问题,让数据流图变得更加清晰。Spark是在大数据处理过程中通过数据流图(DAG)来描述计算过程的一种方式。Spark将分布式文件系统上的数据抽象为RDD,可以自由的用Spark的编程接口对这些数据进行处理。
MR每一步操作后都需要将结果写入文件系统,但是Spark可以自由决定将哪些中间结果放在内存中,以供后续操作进行复用,大量的减少了与分布式文件系统进行交互的频率。
back.