1. Why FaRM
FaRM使用了optimistic concurrency control,这是FaRM使用的技术中我们最感兴趣的一项。按照课程规划,FaRM这篇论文是事务和Replication、数据分片这些领域中最后一篇paper。这些新的具备RDMA能力的NIC(Network Interface Controller)拥有巨大的性能潜力,从而激发人们写出了这篇paper。
RDMA支持的NIC(远程直接内存访问支持的网络接口控制器)是一种高级网络接口芯片,它在计算机之间实现直接内存访问。RDMA允许一个计算机直接将数据传输到另一个计算机的内存中,从而减少了CPU开销和系统资源的使用。这将提高网络吞吐量并降低数据传输延迟。
要使用RDMA技术,您需要RDMA功能支持的NIC、与其兼容的交换机以及软件堆栈。典型的RDMA协议包括InfiniBand、RoCE(融合以太网上的RDMA)和iWARP(Internet广域RDMA协议)。
RDMA支持的NIC主要用于提高高性能计算(HPC)、数据中心和云计算环境中的数据传输性能,以及在存储环境中改善数据传输性能。
与Spanner相比,在事务方面,他们俩都使用了replication与2PC。Spanner关注的重点在于Geographic replication(地理区域级别的复制),这使得我们能够在东海岸、西海岸的不同数据中心中建立副本,并且在处理涉及许多不同地方的数据的事务的能力也很高效(分布式事务)。
FaRM是一种研究原型,并不是一个已经完善的产品,FaRM的目的在于探索这些新的RDMA高速网络硬件的潜力。它假设的场景是,所有的replica都在同一个数据中心,如果这些replica是类似于spanner一样在不同的数据中心,那么这种设计就没有意义了,FaRM并不会试着去解决Spanner要解决的问题,FaRM的容错能力范围可能是针对于单个服务器的崩溃;因此当一整个数据中心发生供电故障时,只有当供电恢复后,它才会试着去恢复数据。
FaRM使用的RDMA技术已经严重的限制了设计选项。
我们要明白Spanner与FaRM针对的是不同的瓶颈。Spanner中人们担心的主要瓶颈在于卫星信号传播上的延迟以及数据中心间的网络延迟;在FaRM中,主要瓶颈在于服务器上的CPU时间,因为设计者们希望将所有的replica放在同一个数据中心中,以此来消除卫星信号和网络传播所来带的延迟。
2. FaRM设计概要

FaRM将所有的replica放在同一个DC中运行,有一个CM(配置管理器),CM会决定每个数据分片中哪个server是primary,哪写服务器是backup,当然CM还需要ZK帮助它做到使所有的server的配置统一。
2.1 FaRM的replication设计(可以是n个replicas)
FaRM根据key将数据进行分片并分散到一堆primary-backup pairs上去,即每个数据分片会被存到两个replica上:一个是primary、一个是backup(replica的身份赋予由CM负责)。每次更新数据的时候,priamry和backup上的数据都必须被及时更新,因此这些replica并不是由Paxos之类的共识算法来维护的,相反,在FaRM中,我们规定当某一个服务器中的的分片数据发生变化时,那么该分片所在的所有服务器都必须及时的应用这个变化。
FaRM规定read只能在primary处进行。因此这意味着,只要给定的数据分片所在的服务器集群中有一个replica是可用的,那么这个数据分片就可以及时的提供服务,故这种方式只需要一个活着的replica即可,而不是大多数。
当然每个数据分片可以不只有两个replica,也可以有多个,如f+1个replicas可以容忍f个replica发生故障。
2.2 Txn Coordinator(TC)
2PC当然需要事务协调器(TC),可以把TC当做独立的client来看待,在论文中,他们将TC与FaRM的存储服务器放在同一台机器上运行,但是这些作为client的TC可以去执行事务。从另一种角度,可以理解为FaRM的client负责接收用户发来的请求,并执行相应的事务,同时这些client也在2PC中扮演了事务协调器的角色。
2.3 For Better performance
为了更好的性能,FaRM使用了一些tricks来提高自己的性能,同时这也是这篇文章中我们要关注的一些点:
2.3.1 sharding
对数据进行分片,论文中,他们把数据进行拆分到90台服务器上,当在不同的数据分片上进行的操作是彼此独立的时候,就可以获得极大地并行性能。
2.3.2 RAM替代disk
FaRM将所有的数据都放在了服务器的RAM中,而不是放到服务器的磁盘上。对于普通RAM而言,断电后里面存储的内容就会消失,因此FaRM为了容忍供电故障,FaRM使用了NVRAM(non-volatile)非易失性的RAM来解决RAM因供电故障而导致数据全丢失的情况。
2.3.3 RDMA
RDMA技术,通俗来说就是,在不对服务器发出中断信号的情况下,通过服务器的NIC(network interface cards)网络接口卡来接收数据包,并通过指令直接对服务器内存中的数据进行读写。
这种技巧通常被称为kernel bypass,这意味着,可以在不涉及内核的情况下,应用层代码可以直接访问网络接口卡,并完成对目标服务器内存的读写。
3. NVRAM(non-volatile)
这个主题不会直接影响FaRM的整个设计的其他部分。FaRM的所有数据都是存放在RAM中的,当一个client所执行的事务对一份数据进行更新时,他需要让存储该数据的相关的所有replicas在各自的RAM中去做这个更新,因此事务会在RAM中对该数据对象进行修改,也就无需再到磁盘上进行落盘操作了,这节省了大量的时间。
3.1 问题引入
当遇到供电故障,RAM就会丢失它存储的内容,虽然每次更新都会同时传播到分片所在的所有replicas,但是我们知道所有的replicas都在一个数据中心中,因此站点范围内的供电故障会让所有服务器的RAM中的数据丢失,所以这并不符合我们做出的不同服务器所发生的故障是互不相干的假设。
所以我们需要一种方案,当整个DC的供电都出现问题时,系统依然可以正常工作。
3.2 解决方案
FaRM在每个rack(机架)上都放了一个大电池,这些电池形成了一个临时的供电系统;若电池检测到了系统发生了供电故障,那么这些电池就会自动接收对服务器的供电工作,并让所有机器继续运行。
由于这些电池的容量并不大,只能让系统再坚持大概10分钟,所以当电池接管工作时,他会向系统中的所有服务器发出消息,告诉他们只有10分钟的运行时间了,此时FaRM会停止系统中所有服务器的所有操作,接着它会将每台服务器RAM中的所有数据复制到该服务器挂载的固态硬盘上,一旦完成复制(如果这些操作能在电池的供电期间完成,当然是最好的,我们不清楚会不会存在不能完成的情况,一般是可以完成的),机器就会关机。
因此,当遇到大范围的供电故障时,依赖这些电池,所有机器可以将他们RAM中的数据保存到磁盘,当该数据中心的供电恢复时,服务器可以从自己挂载的固态硬盘中读取保存的内存镜像,恢复RAM中的数据。
所以这就确保了服务器不会因为供电故障而丢失他们已经持久化的状态。本质上是使用后备电源完成把RAM数据落到本地磁盘上保证了RAM的非易失性,使得数据能够从供电故障中活下来。
3.3 不足
3.2中的方案只对供电故障有效,即只有当后备电源注意到主电源发生了故障,它才会顶替上去。这就意味着,如果有其他的原因导致服务器发生了故障(如硬件故障、软件中存在bug等等),那么NVRAM策略对此束手无策,所以FaRM使用了f+1个replicas的策略在一定程度上容忍这些故障。
此外,若DC中出现了故障,且该DC无法再恢复供电,那么就需要通不过物理手段来移动磁盘和服务器,把他们移动到新的DC,如Amazon用货车迁移数据,但是这不是FaRM设计人员需要考虑的情况,他们假设DC的供电故障总是可以被恢复的。
3.4 总结
本质上来说,NVRAM方案消除了系统在持久化写操作方面的性能瓶颈,剩下的瓶颈就是网络和CPU这两个方面了。
在FaRM剩下的设计中,我们可以将NVRAM忽略掉,因为除了故障时将数据写入磁盘之外,设计中的其他部分都不会与NVRAM有直接的交互。
4. Network transmission
FaRM的网络传输部分需要借助具有RDMA功能的NIC单独定制一套服务器通信方法,传统的服务器通信方法无法适配FaRM极快的事务处理速度。
正如上面所说,当我们通过NVRAM方法消除了将数据持久化磁盘的性能瓶颈,剩下的问题就在CPU与网络这块了。教授提到了很重要的一点,在许多的分布式系统中,它们都会存在一个巨大的瓶颈,他们需要通过CPU时间来处理网络交互,因此CPU会成为性能上的一个综合瓶颈,这与传统的服务器间的通信方式有关系。
但是FaRM中不存在任何网速上的问题,设计人员花了大量时间与精力来消除服务器间数据交换的性能瓶颈。但是我们有必要了解一下服务器间通信的传统方式是什么。下图是传统的服务器之间网络通信流程图。
虚线之上是用户态,虚线之下就是内核态,实线分割硬件层与内核层。从顶层到下层依次进行说明:
4.1 Network-traditional
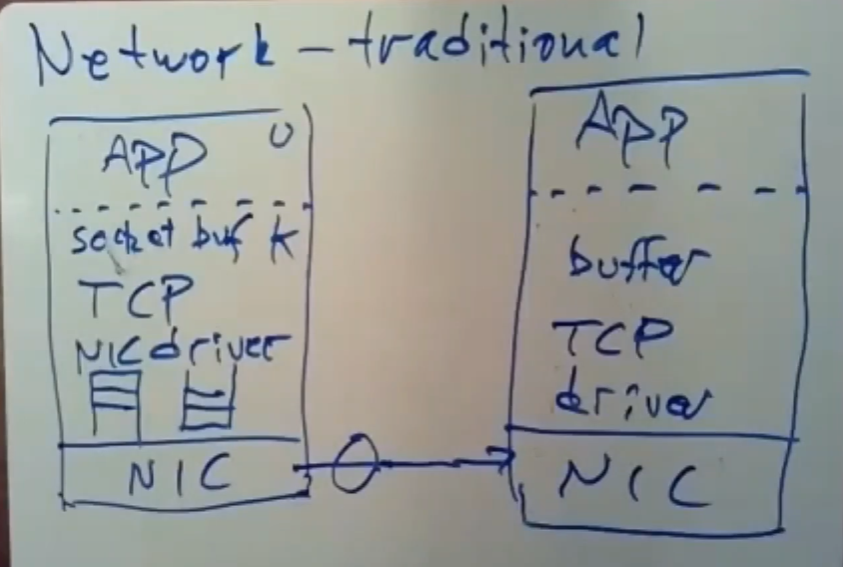
4.1.1 用户层
通常来说,当一台服务器想要去发送一条RPC消息时,我们可能会有一个应用程序,该程序在用户态空间运行,用户态与内核态之间有一条界限。为了发送数据,应用程序得调用内核中的系统调用,但是这样做的成本并不低,此外,内核中还存在着一大堆软件,我们要通过它们在网络中发送数据。
4.1.2 内核层
如图所见,第一层是socket层,也称之为是socket buffer,它的作用是对数据进行缓存,这涉及到复制数据,缓存操作需要花一些时间。
再往下是一个复杂的TCP协议栈,它知道关于重传、序列化、checksum以及flow control等等相关的所有的事情。在这里同样需要做很多处理,也需要花费一定的时间。
内核中存在着某种NIC驱动,它所做的就是通过NIC直接从主机内存中读取/写入数据包,所以这里会有两个队列之类的数据结构:一个里面放着NIC通过DMA访问目标服务器内存时所拿到的数据,之后就等待内核去读取这个队列中的数据包;另一个队列用于保存对外发送的数据包,这样NIC可以方便的将数据发送出去。
4.1.3 硬件层
最底层是一个叫做网络接口卡(NIC)的硬件,内核可以对它上面的一堆寄存器进行通信与配置,NIC也有可以通过电缆将bit信息发送到网络上的硬件。
4.1.4 接收方
发送方要发送消息时,应用程序要发的数据会一层一层的向下走,最后通过NIC发送bit信息。
接收方对信息的处理是由底层到上层的,与发送方相反:在接收方的NIC收到这个信息后,它会发送一个中断信号给内核,内核会通过NIC驱动将数据包发送给TCP进行处理,这些被TCP处理过后的数据包会被写入socket buffer,并且等待应用程序去读取这些数据。
在某个时刻,应用程序会去读取socket buffer里的数据,通过系统调用将内核buffer中的数据拷贝到用户态空间里。
4.2 traditional-network总结
不难看出,传统的服务器间的通信方式需要大量的软件参与、需要大量的处理,以及很多十分消耗CPU资源的操作,如:系统调用、中断、复制数据。因此传统的网络通信方式速度是比较慢的,它的通信速率距离FaRM所要达到的性能目标而言还是太少了。
传统通信方式很难做到每秒传输数十万条RPC消息,虽然看起来很多,但是依然无法满足FaRM的性能要求;并且这也远远小于NIC通过网线传输数据速率的上限,网线传输的速率一般是10Gbit/s,即上限可能是每秒发送百万、千万级别的RPC消息;
但是数据库通常需要使用的信息大小很小,在这种情况下,我们很难去写一个RPC软件,使之每秒能够生成10Gbit大小的消息,所以很难进一步的提高发送速率。
4.3 FaRM的网络传输方案
FaRM使用了两种技术实现对网络传输速率的大幅提高:kernel bypass技术与具有RDMA功能的NIC。
下面用APP指代应用程序这个名词。
4.3.1 kernel bypass
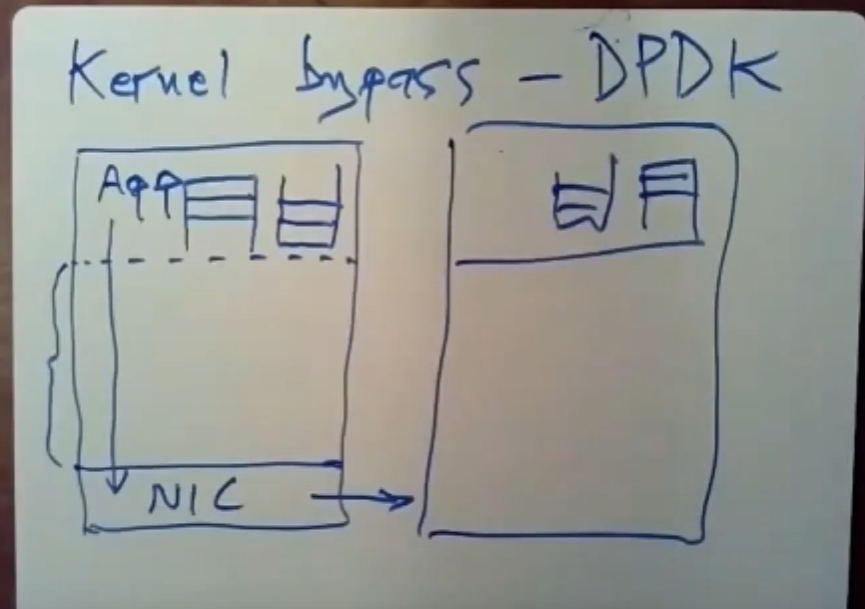
与其让应用程序通过调用复杂的内核代码来发送所有数据,我们可以通过对内核保护机制进行配置,以此来让应用程序直接访问NIC。在FaRM中,APP实际上可以越过内核态直接去访问NIC上的寄存器,并告诉NIC该发送什么数据,NIC通过DMA也可以直接访问app那部分内存,APP与NIC在不需要内核态的情况下,二者可以直接相互通信。
比如,不需要内核的参与,APP可以直接看到哪些信息已经到达了,发送队列与接收队列直接被设置到了APP处,NIC通过DMA访问APP处的发送队列,可以直接把数据发送出去。
现在我们就消除了所有涉及网络的内核代码调用,这就保证了内核不会参与网络通信,这里没有系统调用,没有interrupt中断,APP可以直接对内存进行读写,NIC可以直接看到这些内容。在通信这部分直接忽略内核即可。
最新的网络接口卡可以做到这些,但是这需要APP去做原来TCP为我们做的那些事情:checksums、重传等等。实际上我们可以自己来做到这些事情,FaRM的kernal bypass机制使用了DPDK工具包,它是开源的,使用它可以写出性能非常高的网络应用程序。
APP可以直接与NIC通信,NIC通过DMA能看到写入APP内存中的数据。这意味着可能需要对OS的内核进行修改来做到kernel bypass机制。此外,我们也需要一个相当强大的NIC,现代的NIC知道如何跟多个APP的不同的队列通信。
4.3.2 具有RDMA功能的NIC
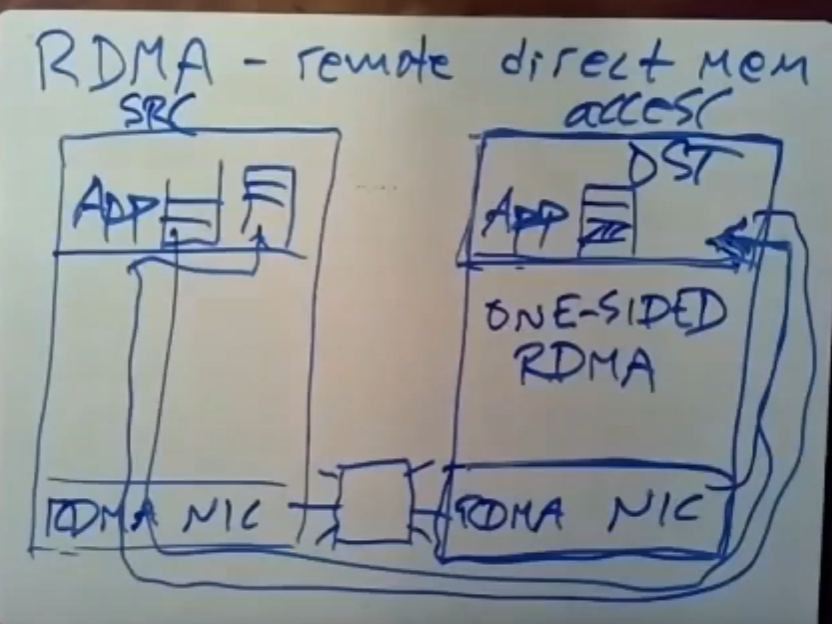
这些支持RDMA的NIC通过网线连接,中间会有一台交换机,很多不同的servers与它连接在一起,通过交换机任意两个server之间可以相互通信。
SRC服务器可以通过RDMA系统发送一条特殊的消息来通知NIC,使它直接对目标服务器的APP的地址空间中的内存直接进行读写操作。所以这种新的NIC可以对目标APP的内存直接进行读写操作。SRC与目标二者都分别有接收队列与发送队列,目标会将请求结果直接返回给src的接受队列。
比较厉害的一点是,目标服务器上的CPU与APP对通过RDMA-NIC进行的读/写操作完全不知情,读/写操作完全是在RDMA-NIC的固件中执行的,因此这里不会发生interrupt、中断,APP也不用考虑请求与响应之类的事情。目标主机上的网络接口卡只需要去对应用程序内存进行读取或写入操作,然后将结果返回给源应用程序即可,目标服务器上的CPU与APP啥都不用管。
这种做法的开销会很低很低,因为我们只需要对目标服务器中的目标APP的RAM中的数据进行读写;通过将kernel bypass机制与RDMA-NIC硬件一起使用,这使得我们在服务器之间进行简单地读和写的时候,要远远地比通过普通的RPC调用发送消息的方式快的多的多。因为我们不需要用到内核,不需要内核态。
4.4 FaRM通信机制的思考
我们知道,TCP本身有重复信息检查等很多很棒的特性,在FaRM使用的传输方案中,它舍弃了TCP协议,但是这些RDMA-NIC本身使用的是自带的可靠的sequenced protocol,这与TCP很像,但不是TCP。所以当我们使用RDMA-NIC进行读/写操作时,他会一直保持传送数据的状态,直到我们的请求丢失或者得到一个响应为止。
SRC主机会去询问自己的NIC该请求是成功还是失败了,会拿到一个确认信息。所以我们舍弃了TCP,我们失去了TCP中大多数很好的特性,并且我们要知道,FaRM的通信机制只在本地网络中有用,即所有的机器都在一个数据中心时的场景,如果跨数据中心,其实RDMA的性能没有我们想的那么快。
FaRM使用单向RDMA对目标服务器上内存中的数据进行读写,但有时FaRM也会使用RDMA通过RPC之类的协议来发送一些消息:比如说FaRM有时候使用RDMA给目标服务器的接收队列中追加消息,这里的消息始终是写操作相关的消息。
在事务存在的前提下,只使用RDMA操作是不被允许直接修改数据的。
因为不使用内核的中断机制,所以目标服务器会做轮询操作:定期对内存中接收到的信息进行检查,看是否有人给自己发送消息。所以,FaRM中使用RDMA的场景不仅仅是读和写,也可以使用RDMA给另一台服务器追加消息或者日志条目。
4.5 性能比较
使用RDMA进行简单地R/W操作导致的延迟只有5微秒,相比于网络通信的一般时延来说,这已经很快很快了。所以,我们通过单向RDMA操作来直接对保存在数据库服务器内存中的记录进行读和写,我们不需要和目标服务器的软件与CPU进行通信,所以用很低的时延就能拿到数据。
5. FaRM的事务机制-OCC
5.1 问题引入
单向RDMA能带来很大的读写性能提升,但是问题在于我们是否可以只用单向RDMA来实现事务。即不用发送那些必须由服务器软件进行解释的消息(如2PC涉及到的消息),只使用RDMA来对服务器中的数据进行读或写?
答案是No,在事务中使用RDMA的难题在于replication和数据分片,在目前为止我们看到的所有用来处理事务、复制的协议,都是需要服务器软件参与的,如2PC需要服务器软件判断一条记录上面是否有锁,但是RDMA就很难去做到这一点;Spanner中用版本号实现了并发控制,服务器会根据版本号去判断数据的可见性(是否被提交)。
上面提到的这一切似乎都需要服务器软件的参与,仅靠RDMA似乎是无法直接兼容事务和replication的,因此我们不允许使用单向RDMA直接对数据进行修改操作。
为了让FaRM能使用RDMA并且对事务进行支持,他们使用的主要手段就是乐观锁并发控制(OCC)。
5.2 并发控制机制复习

并发控制机制分为悲观与乐观两大类。这块内容的说明可以去11 Distributed Transactions这章去复习一下,里面较为详细的说明了悲观与乐观方案的实施过程,与上图要说的内容是一致的。
FaRM中的RDMA-NIC并不具备使用锁策略的能力,即如何识别一条记录本身是否被上锁了。所以FaRM使用了OCC,在事务执行时只管去读/写自己需要的数据,但是结果会保存到自己的本地buffer中(事务结束前对外界不可见),最后会有一个validation阶段,若无冲突,则可以提交;若有冲突,那么立即中止该事务,并试着重新执行。此外,读取操作不需要使用锁,即读取操作可以使用单向RDMA来进行。
弄清楚
validation阶段做了什么事情,如何鉴定是冲突或不冲突,将会是接下来的一个重点。
5.3 FARM API

FaRM的研究原型并不支持SQL之类的东西,FaRM的API更像NoSQL数据库的API,在某种意义上,可以把FaRM看作带事务的NoSQL数据库。
上图是FaRM执行事务的一个例子,上面的函数都是FaRM库中的可调用API。txCreate()函数用来声明一个新事务,txRead()会直接读取相关服务器上的数据;txWrite()只会对本地buffer中的数据进行修改。txCommit()函数中有validation所需要的一些操作,返回值代表验证阶段通过与否,只有当返回值为true,即验证阶段通过后,该事务才会最终把本地buffer中更新的数据写回到服务器中。
论文中的Figure4描述了
txCommit()函数的行为,较为复杂,在下面会讨论一下。
上图中的OID是objectID,它是一个复合标识符:<region,address>。通过region确定目标数据所在的主副本位置,之后client告诉RDMA-NIC:请通过address去目标主副本拿到这个具体的数据。
因为所有服务器的内存会被拆分成不同的regions进行管理,CM回去跟踪服务器复制的
region number(全局唯一)是什么,每个服务器负责维护的region副本都不同,确定了region后,让RDMA-NIC用address去对应的region获取对应地址的数据。
5.4 server memory layout
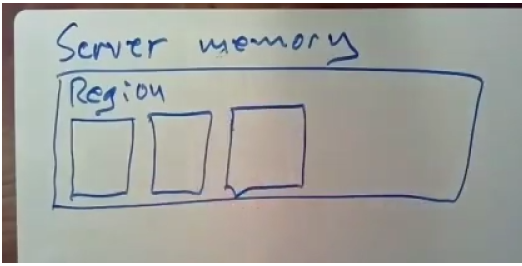
在一台服务器的内存中包含了一个或多个数据区域,一个区域中包含了一堆objects,下图中表示了一个region中的object的结构:
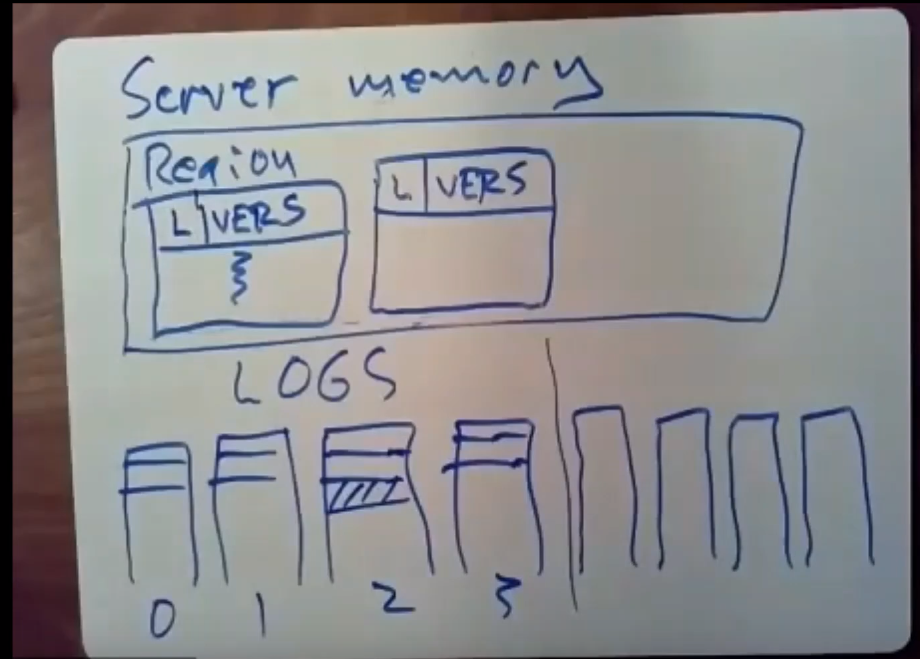
可以看到每个object的结构都是相同的,高位处是一个lock标志位,低位处放对象的当前version number,剩下的空间存放该对象的实际数据。当系统对一个对象进行修改时,他会对该对象的版本号+1。
左下角:每个服务器都会有自己的一份log日志队列,可以通过RDMA的方式追加日志,每台服务器的日志记录着自己所执行的事务的情况,这些日志是非易失的,因为我们有NVRAM。
右下角:是一组单独的消息队列,用于处理RPC那样的通信,每个服务器都有N^2^ 个消息队列,其他服务器可以通过RDMA来对该服务器的incoming message queue来进行写入操作。
在 FaRM 系统中,每个服务器有 N² 个队列的原因与系统设计有关。FaRM 使用 RDMA 技术提供低延迟、高吞吐量的内存访问,这个技术允许一个节点直接访问另一个节点的内存而无需经过操作系统或进程间通信,从而降低延迟并提高整体性能。 为使 RDMA 连接的建立和管理更加高效,FaRM 中使用 N² 个队列的设计。这里的 N 指的是服务器的数量。这种设计可以让每个服务器都有一个专门的队列与其他服务器相互通信。具体来说,每个服务器需要 N-1 个发送队列和 N-1 个接收队列,与其他 N-1 个服务器相互通信。因此,整个系统中总共有 N*(N-1) 个队列。 这种 N² 个队列的设计使得节点之间的通信和内存访问更加顺畅和高效,因为每个服务器之间都有一个专用的通道进行通信,从而降低了竞争和延迟。然而,这种方法的一个缺点是它在大规模集群中可能导致较高的配置和管理开销,因为队列数量会随着服务器数量的增加呈平方增长。虽然如此,对于许多高性能计算任务,这种设计仍然是有利的,因为它提供了高吞吐量和低延迟的内存数据访问。
6.FaRM Commit protocol-OCC
这一部分是重点,因此单独开了一个章节进行说明:
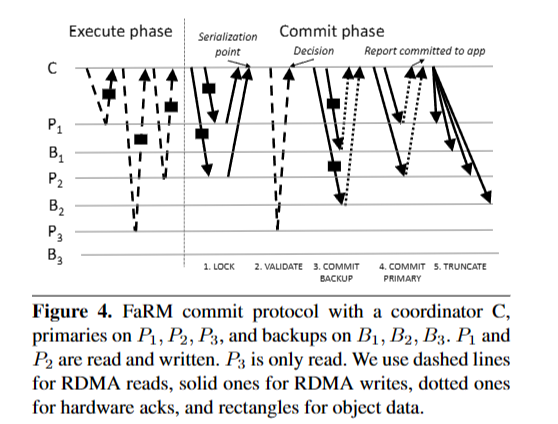
图4:在FaRM(Fast Remote Memory)的提交协议中,有一个协调器C,主节点位于P1、P2、P3,备份节点位于B1、B2、B3。节点P1和P2被读取和写入,节点P3仅被读取。我们用虚线表示RDMA读取,实线表示RDMA写入,点线表示硬件确认,矩形表示对象数据。
上图解释了FaRM所使用的OCC提交协议,重点会讲述这个图中的各个阶段。单向RDMA读取操作不用去检查对象当前是否被加锁,所以这也意味着单向RDMA读取是不可能失败的,此外,无论读到的对象后续是否会被修改,下面都会有相应的机制对其进行检查。
6.1 Execute phase
这个阶段进行的是client端事务所做的R/W操作,当client需要读取数据时,或需要修改某个数据时,它首先会用单向RDMA操作来读取相关primary服务器内存中的数据,他需要先获取此时目标object的版本号。
下面进入commit phase。
6.2 LOCK
这一步只对事务中要修改的对象起作用。
client处调用txCommit函数时扮演了事务协调器的角色,在lock phase中,事务协调器发送lock log给对应的primary,等待primaries去验证处理这些消息后,回复协调器。
无论是什么操作,都会以Log的形式发送到服务器的log日志中,等待服务器的轮询处理,服务器处理到这个log时,会应用该log对应的操作,完成log对应的行为。
具体来说,client会给每个primary发送它要访问的object ID、一开始获取的版本号、以及更新后的内容,将上述内容作为一个新的log条目追加到primary的日志上。上图中意味着这个事务要对两个不同对象进行写入操作。
primary要主动去处理这些日志条目,它需要做一大堆检查来验证该事务中的这个primary所负责的部分能否进行提交:我们得等待每个primary对它自己内存中的client日志进行轮询,检查是否有新的日志条目,如果有新的日志条目,就对其进行处理,接着,发送Yes或者No来告诉client它能否去执行该事务中的这部分操作。
当primary轮询到该log条目时,需要做出如下检查:
- 该object ID对应的对象是否已经被锁上了,如果是,那么拒绝这个log消息,用RDMA回复client一条No消息,这会导致事务协调器中止事务
- 若没有被上锁,primary所做的另一件事就是去检查它的版本号,它会去确保client发送给它的版本号和client一开始读取该数据时的版本号是一致的,如果版本号发生了改变,这意味着,当我们的事务在执行读和写的期间,其他人对该数据对象进行了写入操作,该数据对象的版本号就会发生改变,那么primary就会给client回复一个No,并禁止该事务继续执行。
- 若该事务对象版本号没有改变、且也没有被上锁,那么,primary就会对该数据对象加锁,并返回一个成功的信号给client。
因为primary通过多CPU来执行多线程任务,这里面可能也有一些其他事务,同一个primary上的其他CPU可能会去读取其他client在同一时间传入的log队列,不同事务间可能存在着竞争的情况。或者是,有几个不同的事务要试着对同一个对象进行修改所导致的抢锁。
So,实际上,primary会使用一个原子指令(即compare-and-swap)来检查版本号以及锁,然后,它会执行一个原子操作,即对该数据版本进行上锁,So,这就是为什么要将lock标志位放在高位,而版本号放在低位的原因了,So,这样我们就可以通过一条指令来对版本号和lock标志位进行compare-and-set操作了。
注意,如果该事务对象已经被锁住了,那么直接返回给client一个No即可,无需等待;之后协调器及时中止该事务,只要有一个参与者的primary投了No,那么协调器就要中止这个事务。
6.3 Validate(for RO txn)
这一步只对事务中的只读对象起作用。所以只读事务是不用经历LOCK phase的。
事务协调器可以通过单向RDMA读取来进行验证阶段,这样我们就无须将东西放入日志并等待primary去查看我们的日志条目对其进行处理了,本质上来讲,它代替了对象锁的作用,因此它可以让只读变得更快。
对于只读事务或一个事务的只读部分的数据对象而言,在validate阶段,事务协调器会去刷新这些数据对象的header,并检查当前版本号是否和它一开始读取该对象时的版本号一致,也会去检查这里的锁是否被释放;而不是像LOCK阶段那样需要发送log等待primary的处理。
所以FaRM的只读事务的处理速度是非常快:在 FaRM(Fast Remote Memory)系统中,单向 RDMA(Remote Direct Memory Access)读操作可以直接访问远程节点的内存,而不需要远程节点的 CPU 参与。这样,它可以在不进行 CPU 轮询消息队列处理的情况下直接获取数据,从而实现更高的性能和低延迟。
这种特性使得 RDMA 技术尤其适用于分布式系统和并行计算,因为它减少了通信开销并降低了系统之间数据传输的延迟。
6.4 Commmit backup
用于实现容错,具体细节可见论文,课上教授并没有对这块进行具体说明。
6.5 commit primary
当确定可以提交后,事务协调器进入commit primary阶段,在这一阶段事务协调器会往每个primary的日志中追加日志条目(commit-primary),事务协调器等待收到来自RDMA-NIC的ACK消息,它无需等待primary去处理这些commit-primary记录,只要事务协调器收到任何primary所发送的确认信息,它就可以返回Yes来表示这个事务已经执行成功(告诉APP这个事务已经提交了)。
primary会去查看这些日志,它们会对这些日志进行轮询,它们会注意到在某一时刻有一个commit primary记录,收到这个commit primary日志条目的primary会知道,它之前将这个对象锁住了,并且这个对象必须依然被锁住,So,primary要做的事情就是,使用先前收到的log消息中的新内容来更新其内存中的这个对象,更新该对象的版本号,清除该对象上的锁。
6.6 Truncate
一旦所有primary知道事务协调器已经提交了这个事务,那么你就可以告诉所有primary,它们可以丢掉与这个事务相关的日志条目了,当然在丢弃之前,这些primary必须事先apply完成这些log(论文中有类似的说法)。
7. conclusion
FaRM中的所有东西都很精简,读取都是流式操作,这种流式操作会很快(部分原因是因为RDMA)。
OCC允许事务在不检查锁的情况下直接读取,并且使用单向RDMA后,可以不经过内核层直接去访问数据,这样就更快了。事实证明,如果没有什么冲突发生,那么乐观锁并发控制的效果就会很棒,如果一直发生冲突的话,那么事务就得被中止。
但是FaRM中还存在着一系列限制:所有的数据都必须放在内存中、所有的服务器都必须放在一个数据中心。
但是就分布式事务的速度而言,它真的很快,比目前生产环境中的任何系统的速度都快,但是它的使用条件也比较苛刻:NVRAM、RDMA-NIC这些硬件环境是必须的。
但是在性能方面,RDMA在数据中心里面是一种非常受欢迎的技术。
back.