Spanner: Google’s Globally-Distributed Database
1. 摘要
Spanner是谷歌的可扩展、多版本、全球分布式和同步复制的数据库。它是第一个将数据分布在全球范围内并支持外部一致性分布式事务的系统。本文描述了Spanner的结构、功能集、各种设计决策的基本原理以及一种新颖的时钟API,该API公开了时钟不确定性。这个API及其实现对于支持外部一致性和各种强大的特性至关重要:过去的非阻塞读取、无锁只读事务以及跨Spanner的原子模式更改。Spanner使用shards(数据分片),采用paxos一致性算法。
1.1 外部一致性定义
外部一致性是指在分布式系统中,当多个事务并发地访问和修改同一份数据时,系统应该保证它们看到的数据是一致的(这里强调的是一致性,并非是正确性)。具体来说,外部一致性要求多个事务在执行过程中所看到的数据必须满足以下两个条件:
-
与单机系统一样,每个事务在读取和修改数据时都必须遵循事务的隔离级别,保证数据的正确性和一致性。
-
不同于单机系统,分布式系统中的多个节点必须在时间和顺序上保证操作的一致性,即不同节点之间的操作必须按照一定的顺序执行,以保证最终结果的正确性和一致性。
外部一致性是分布式系统中非常重要的一个概念,因为它直接涉及到数据的正确性和可靠性。在实际应用中,外部一致性通常需要对分布式系统进行复杂的设计和实现。这个概念是在Spanner中第一次被提出的,但是实际上外部一致性与线性一致性的概念是相同的。
1.2 spanner的诞生(与bigtable的对比)
Bigtable对于某些类型的应用程序来说使用起来很困难:那些具有复杂、不断发展的模式,或那些希望在范围广泛的复制环境下实现强一致性的应用程序。
Google的许多应用程序选择使用Megastore [5],因为它具有半关系数据模型和支持同步复制,尽管其写吞吐量相对较低。因此,Spanner已经从类似于Bigtable的版本化键值存储演变为时间多版本数据库。数据存储在模式化的半关系表中;数据被版本化,每个版本都自动标记了其提交时间戳;旧版本的数据受可配置的垃圾回收策略的影响;应用程序可以在旧的时间戳上读取数据。Spanner支持通用事务,并提供基于SQL的查询语言。
spanner在版本管理与查询方面比bigtable做的更多,有更多的功能。
- Bigtable的版本化键值存储与Spanner的时间多版本数据库的区别在哪?
版本化键值存储和时间多版本数据库都是用于存储和管理数据的系统,但它们之间存在一些区别,主要在数据模型和事务特性两个方面。
版本化键值存储(如Google的Bigtable)是一种键值存储系统,它将数据存储为无结构的字节数组,并使用键来区分不同的数据。它支持按键范围进行数据扫描和按键查询,但不支持传统关系型数据库的SQL查询和事务特性。Bigtable使用时间戳来跟踪和管理数据的版本,但它只存储最新版本的数据,并不存储旧版本的数据。这使得Bigtable非常适合于高吞吐量、低延迟的应用程序,例如MapReduce等批处理作业。
时间多版本数据库(如Google的Spanner)是一种半关系数据库系统,它将数据存储为结构化的半关系表,并支持SQL查询和关系型数据库的事务特性。Spanner使用时间戳来跟踪和管理数据的版本,并存储所有历史版本的数据,这使得应用程序可以读取到过去的数据版本。Spanner还支持跨数据中心的同步复制和全局分布式事务,这使得它非常适合于需要高可用性和强一致性的应用程序。
因此,版本化键值存储和时间多版本数据库在数据模型、查询语言和事务特性等方面存在一些差异,开发者需根据不同的应用场景选择合适的系统。
- 什么是半关系数据库系统,什么是半关系数据模型?
半关系数据库系统是一种介于关系型数据库和非关系型数据库之间的数据库系统。它是在关系型数据库理论的基础上发展而来的,但与传统的关系型数据库不同,半关系数据库系统不强制要求数据模型必须满足关系完整性约束条件,例如实体完整性、参照完整性和域完整性等。相反,它允许数据模型存在一些冗余和不完整的情况,以满足某些特定的应用需求。
半关系数据库系统的数据模型被称为半关系数据模型。它是基于关系型数据模型的扩展,具有更灵活的结构和更宽松的约束条件。半关系数据模型允许表之间存在部分重叠和冗余,并且允许表中存在NULL值和重复值。此外,半关系数据模型还支持嵌套关系、多值属性和继承关系等特性,以满足不同的应用需求。
半关系数据库系统通常用于存储和管理半结构化数据,例如XML和JSON等格式的数据。它们在处理复杂的数据结构和数据关系时比传统的关系型数据库更具优势,因为它们允许更灵活的数据模型和更宽松的约束条件。同时,半关系数据库系统还可以运用关系型数据库系统的部分优势,例如支持SQL查询和事务处理等特性。常见的半关系数据库系统包括Google的Spanner和Megastore等。
- 论文中说spanner是时间多版本数据库,bigtable只是版本化键值存储,但是了解到bigtable在一个cell中也可以存储一个列族的多个版本数据,所以spanner的优势在哪里呢?
实际上,Bigtable和Spanner都支持版本化数据,具体实现方式也非常相似。在Bigtable中,每个单元格可以存储多个版本的数据(某个列族,如webtable中的contents列,可以保存多个不同时间戳的数据),每个版本都有一个时间戳来标识版本的时间点。同样,在Spanner中,每个数据操作都会生成一个新的版本,并自动标记时间戳来表示版本的时间点。
因此,从版本化数据的角度来看,Bigtable和Spanner的区别并不大。但是,Spanner在版本控制方面做了更多的工作,引入了时间维度的概念,为应用程序提供了更加灵活的历史数据查询和管理方式。
具体来说,Spanner支持时间戳查询,可以查询历史版本的数据,并提供事务性写入和读取操作,保证数据的强一致性和正确性。此外,Spanner还支持可配置的垃圾回收策略,可以根据时间戳或数据版本数量等因素,自动删除或归档旧版本的数据,从而减少存储空间的使用量。
相比之下,Bigtable虽然也支持版本化数据,但是在版本控制方面相对简单,没有引入时间维度的概念,也没有提供时间戳查询和事务性操作等高级功能。此外,Bigtable的垃圾回收策略相对简单,只能配置单元格中最大版本数目,超过该限制后,较旧的版本将被删除或归档。
因此,虽然Bigtable和Spanner都支持版本化数据,但Spanner在版本控制和数据管理方面更加灵活和强大,可以满足更加复杂和严格的应用需求。
作为一个全球分布式的数据库,Spanner提供了几个有趣的功能。
- 首先,应用程序可以动态地对数据进行复制配置控制。应用程序可以指定约束条件来控制哪些数据中心包含哪些数据,数据距离其用户的距离(以控制读取延迟),副本之间的距离(以控制写入延迟),以及维护多少个副本(以控制耐用性、可用性和读取性能)。
- 系统还可以在数据中心之间动态、透明地移动数据,以平衡数据中心之间的资源使用情况。
- 其次,Spanner具有两个在分布式数据库中难以实现的功能:它提供外部一致性的读写操作,以及在时间戳上跨数据库的全局一致的读取。这些功能使Spanner能够支持一致的备份、一致的MapReduce执行和原子模式更新,全部在全球范围内,即使在进行中的事务存在的情况下也是如此。
1.3 spanner亮点
spanner数据库主要使用了下面的两种技术确保外部一致性(spanner能提供外部一致性的读写操作,并在时间戳上全局保持一致性的读操作):
-
Spanner为事务分配全局有意义的提交时间戳,即使事务是分布式的。这些时间戳反映了序列化顺序。为实现外部一致性提供了保证。
-
全局提交时间戳分配的准确性依赖于一种新的TrueTime API及其实现。该API直接暴露时钟的不确定性,Spanner的时间戳保证取决于实现提供的边界。如果不确定性很大,Spanner将会降低速度等待这种不确定性。
Google的集群管理软件提供了TrueTime API的实现。该实现通过使用多个现代时钟参考(GPS和原子钟)来保持不确定性较小(通常小于10ms)。
2. spanner的实现
2.1 spanner分片策略与zone(zone与分片的关系)
本节描述了Spanner实现的结构和理论基础。然后,描述了目录抽象(directory abstraction),该抽象用于管理复制和数据本地性,并且是数据移动的单位。最后,它描述了我们的数据模型,以及为什么Spanner看起来像一个关系型数据库而不是一个键值存储,以及应用程序如何控制数据本地性。
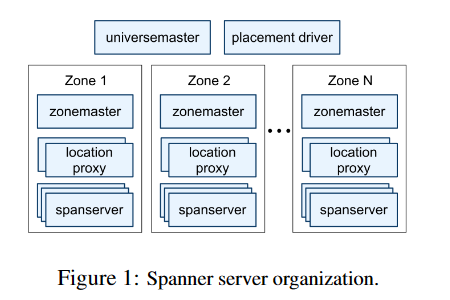
上图展示了Spanner宇宙中的服务器。一个区域(zone)有一个区域主(zonemaster)和一百到数千个分片服务器(spanserver)。前者负责将数据分配给分片服务器;后者为客户端提供数据服务。每个区域的位置代理(location proxies)用于帮助客户端定位被分配为服务其数据的分片服务器。宇宙主(universe master)和放置驱动程序(placement driver)目前只有一个实例。宇宙主主要是一个控制台,用于交互式调试显示所有区域的状态信息。放置驱动程序负责在几分钟的时间尺度上自动移动跨区域的数据。放置驱动程序定期与分片服务器通信,以查找需要移动的数据,无论是为了满足更新的复制约束还是为了平衡负载。由于篇幅限制,我们只会详细描述分片服务器。
Spanner被组织为一组区域(zones),其中每个区域粗略地类似于Bigtable服务器的部署[9]。区域是管理部署的单位。一组区域也是数据可以复制的位置集合。随着新的数据中心投入使用和旧的数据中心关闭,可以向正在运行的系统添加或删除区域。区域也是物理隔离的单位:例如,如果不同应用程序的数据必须分区在同一数据中心的不同服务器集合中,则可能在一个数据中心中有一个或多个区域。
每个区域包含多个Spanner节点(servers)。每个节点包含多个分区(partitions),每个分区存储一个范围的数据,且每个分区都是存储引擎的基本单位。分区是可水平扩展的,并且可以动态地重新分配和移动到不同的节点和区域。
这里的每个节点包含多个分区:在spanserver数量没有那么多的情况下,不同的数据分区存储位于的spanserver可能会发生重叠,这就是所谓的每个节点包含多个分区(partitions)。
在Spanner中,数据分片是按照数据的范围(range)进行的,具体来说,Spanner会将数据按照范围划分成多个数据分区(partition),每个数据分区存储一定范围内的数据,并由一个Spanner节点负责管理。每个数据分区的大小通常是一定的,可以根据实际需求进行调整。
每个数据范围都被分配给一个或多个数据分区,每个数据分区由一个Spanner节点负责管理,该节点存储该分区范围内的全部数据。在实际部署中,Spanner通常会将多个节点分布在不同的Zone和数据中心中,并将数据复制到多个节点和Zone中。这样做可以确保即使某个Zone或节点发生故障,数据仍然能够被访问和操作。(同时,数据的范围可以是重叠的,也可以是不重叠的,看具体的设计策略)
数据分片按照范围进行划分的好处是可以实现数据的均衡分布和高效查询。Spanner将数据划分成多个范围,每个范围对应一个数据分区,每个数据分区都存储了一定范围内的数据。这种划分方式可以让Spanner系统更好地扩展,支持大规模的数据存储和高并发的数据访问。同时,它还可以让Spanner系统在查询数据时只需要访问与查询范围相交的数据分区,从而减少数据的传输和处理,提高查询效率。
2.2 spanner软件栈
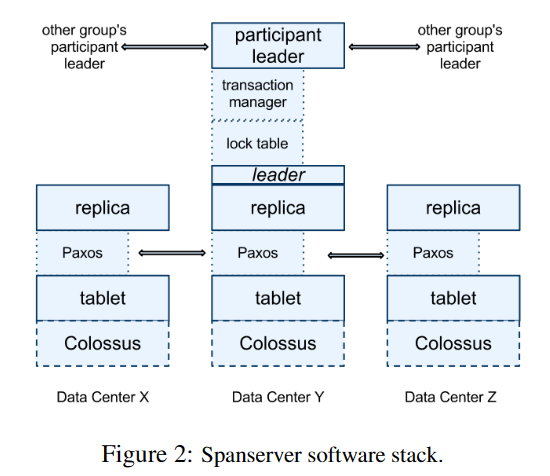
本节重点介绍分片服务器实现,以说明复制和分布式事务是如何被分层到我们基于Bigtable的实现中的。软件栈如图2所示。在底层,每个分片服务器负责100到1000个被称为tablet数据结构实例。一个tablet类似于Bigtable的tablet抽象,它实现了以下映射的集合:
(key:string, timestamp:int64) → string
与Bigtable不同,Spanner为数据分配时间戳,这是Spanner更像多版本数据库而不是键值存储的一个重要方面。一个tablet的状态存储在一组类似B树的文件和一个WAL中,所有这些都存储在一个名为Colossus的分布式文件系统上(它是Google文件系统[15]的后继系统)。
为了支持复制,每个Spanner服务器在每个分片上实现一个单一的Paxos状态机。(早期的Spanner版本支持在每个分片上支持多个Paxos状态机,这样可以实现更灵活的复制配置。但是,那种设计的复杂性使我们放弃了它。)每个状态机将其元数据和日志存储在相应的分片中。我们的Paxos实现支持具有基于时间的领导者租约的长寿命领导者,默认情况下为10秒。
当前的Spanner实现将每个Paxos写入两次记录:一次在分片日志中,一次在Paxos日志中。出于便利性考虑,我们可能会在未来解决这个问题。我们的Paxos实现是流水线化的,以提高Spanner在WAN延迟存在的情况下的吞吐量;但是,Paxos仍然按顺序应用写入(这一点在第4节中很重要)。
这里我们不能确定Paxos日志与分片日志的内容与格式是否是完全相同的,但是一般是不同的。
Paxos状态机用于实现一个一致复制的映射集合。每个副本的键值映射状态存储在相应的分片中。写入操作必须在领导者处启动Paxos协议;读取操作则直接访问任何足够更新的副本下的底层分片状态。所有的副本集合是一个Paxos组。
在每个作为领导者的副本上,每个Spanner服务器都实现了一个锁表来实现并发控制。锁表包含了两阶段锁的状态:它将键的范围映射到锁状态。(需要注意的是,拥有一个长寿命的Paxos领导者对于有效地管理锁表至关重要。)在Bigtable和Spanner中,我们都设计了长寿命事务(例如,用于生成报告,可能需要几分钟的时间),这在存在冲突的乐观并发控制下表现不佳。需要同步的操作,例如事务读取,会在锁表中获取锁;其他操作则绕过锁表。
在每个作为领导者的副本上,每个Spanner服务器还实现了一个事务管理器来支持分布式事务。事务管理器用于实现参与者领导者;组中的其他副本将被称为参与者从属。如果一个事务仅涉及一个Paxos组(大多数情况下都是这样),则可以绕过事务管理器,因为锁定表和Paxos共同提供了事务性。如果一个事务涉及多个Paxos组,则这些组的领导者将协调执行两阶段提交。一个参与者组被选为协调器:该组的参与者领导者将被称为协调器领导者,该组的从属将被称为协调器从属。每个事务管理器的状态存储在底层的Paxos组中(因此是复制的)。
可以回忆一下在Distributed Txns中学习的将2PC与Raft协议结合起来构建一个具备高可用、容错、具有分布式事务功能的分布式系统,思路与这个是一致的。
2.3 Directories and Placement(目录与放置)
在键值映射集合之上,Spanner实现支持一种分桶(bucket)抽象,称为目录(`directory`),它是一组具有共同前缀(`prefix`)的连续键。(使用directory这个术语是历史的偶然性;更好的术语可能是bucket)。我们将在第2.3节中解释前缀的来源。支持目录允许应用程序通过精心选择键来控制其数据的局部性。
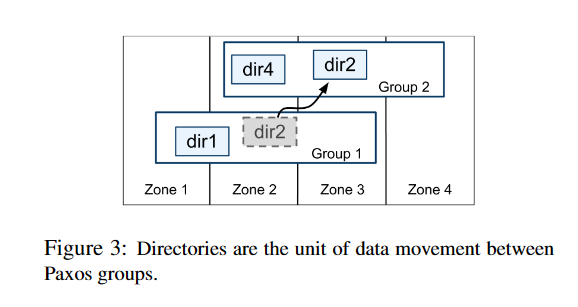
目录是数据放置的单位。目录中的所有数据具有相同的复制配置。当数据在Paxos组之间移动时,它是按目录逐个移动的,如图3所示。Spanner可能会移动目录以减轻Paxos组的负载;将经常访问的目录放在同一组中;或将目录移动到更接近其访问者的组中。目录可以在客户端操作正在进行时移动。可以预期一个50MB的目录可以在几秒钟内移动。
一个Paxos组可能包含多个目录(`directory`),这意味着Spanner分片与Bigtable分片不同:前者不一定是行空间的单个词典顺序连续分区。相反,Spanner分片是一个容器,可以封装行空间的多个分区。我们做出这个决定是为了能够将经常一起访问的多个目录放置在同一个位置。
在某种意义上,一个spanner分片可以理解为是多个bigtable分片的组合。
Movedir是用于在Paxos组之间移动目录的后台任务[14]。Movedir也用于向Paxos组添加或删除副本[25],因为Spanner尚不支持在Paxos内部进行配置更改。Movedir不作为单个事务实现,以避免在大量数据移动时阻塞正在进行的读写操作。相反,movedir注册正在开始移动数据的事实,并在后台移动数据。当它已经移动完成除名义上的一小部分数据之外的所有数据时(即它只剩名义上的这一小部分数据需要移动了),它使用一个事务来原子地移动这个名义上的一小部分数据并更新两个Paxos组的元数据。
目录(`directory`)也是应用程序可以指定其地理复制属性(或放置属性)的最小单位。我们的放置规范语言的设计将管理复制配置的责任分离。管理员控制两个维度:副本的数量和类型,以及这些副本的地理放置。他们在这两个维度上创建了一系列命名选项(例如,北美洲,在1个见证副本的情况下以5种方式进行复制)。应用程序通过使用这些选项的组合来控制数据的复制方式,为每个数据库和/或单个目录打上标记。例如,一个应用程序可能会将每个最终用户的数据存储在自己的目录中,这将使得用户A的数据在欧洲有三个副本,而用户B的数据在北美洲有五个副本。
为了更清晰地说明,我们已经过度简化了问题。实际上,如果一个目录(Directory)变得太大,Spanner会将它分片成多个片段(Fragments)。这些片段可能会从不同的Paxos组(因此是不同的服务器)中提供服务。Movedir实际上是在不同的组之间移动片段,而不是整个目录。
Fragments是Directory(bucket)的一个子集,会在目录太大的情况下进行拆分。
2.4 Data Model
Spanner向应用程序提供以下一组数据特性:基于半关系模式的模式化表数据模型、查询语言和通用事务。支持这些特性的推动因素有很多。需要支持半关系模式化表和同步复制,这是由于Megastore[5]的流行性。谷歌内部至少有300个应用程序使用Megastore(尽管它的性能相对较低),因为它的数据模型比Bigtable更容易管理,并且支持跨数据中心的同步复制。(Bigtable只支持跨数据中心的最终一致性复制。)使用Megastore的知名谷歌应用程序包括Gmail、Picasa、日历、Android Market和AppEngine。
Spanner需要支持类似SQL的查询语言也是显而易见的,考虑到Dremel[28]作为一种交互式数据分析工具的流行程度。最后,Bigtable中缺乏跨行事务引起了频繁的抱怨,而Percolator[32]部分是为了解决这个问题而构建的。一些作者声称,一般的两阶段提交过于昂贵,因为它会带来性能或可用性问题[9,10,19]。我们认为,最好让应用程序员在出现瓶颈时处理由于过度使用事务而导致的性能问题,而不是总是围绕缺乏事务进行编码。在Paxos上运行两阶段提交可以缓解可用性问题。
应用程序数据模型是建立在实现支持的目录-桶化键值映射(`directory-bucketed key-value`)之上的。应用程序在一个宇宙中创建一个或多个数据库。每个数据库可以包含无限数量的模式化表。表看起来像关系型数据库表,具有行、列和版本化的值。我们不会详细介绍Spanner的查询语言。它看起来像SQL,并且有一些扩展来支持协议缓存值域(protocol-buffer-valued-fields)。
Spanner的数据模型并不是纯粹的关系型模型,因为行必须具有名称。更准确地说,每个表都必须有一个有序的一组或多组主键列。这个要求是Spanner仍然像一个键值存储的原因:主键形成了行的名称,每个表定义了从主键列到非主键列的映射。只有当某些值(即使它是NULL)已为行的键定义时,行才存在。强制施加这种结构是有用的,因为它让应用程序通过选择键来控制数据的局部性。

图4展示了一个用于按每个用户、每个相册存储照片元数据的Spanner模式示例。模式语言类似于Megastore,但增加了一个要求,即每个Spanner数据库必须由客户端分成一个或多个表层级结构。客户端应用程序通过INTERLEAVE IN声明方法在数据库模式中声明这些层级结构。在层级结构顶部的表是一个目录表。
目录表中具有键K的每行,以及按字典顺序以K开头的子表中的所有行,他们一起形成一个目录。ON DELETE CASCADE表示删除目录表中的一行将删除任何关联的子行。
上图还说明了示例数据库的交错布局:例如,Albums(2,1)表示用户ID为2、相册ID为1的Albums表中的行。将表交错以形成目录的这种方法非常重要,因为它允许客户端描述存在于多个表之间的局部性关系,这对于分片的分布式数据库的良好性能来说是必要的。如果没有它,Spanner将不知道最重要的表之间的局部性关系。
3. TrueTime(很抽象的一节)

本节介绍了TrueTime API的内容并概述了其实现方式。我们将大多数细节留给另一篇论文,我们的目标是展示拥有这样一个API的强大功能。
上表1列出了API的方法。TrueTime明确将时间表示为一个TTinterval,这是一个具有有界时间不确定性的区间(与标准时间接口不同,标准时间接口不给客户端任何不确定性概念)。TTinterval的端点是TTstamp类型。TT.now()方法返回一个TTinterval,保证包含调用TT.now()时绝对时间的时间间隔。时间纪元类似于具有闰秒平滑的UNIX时间。将瞬时误差界定义为ε,它是区间宽度的一半,平均误差界定义为ε-average。TT.after()和TT.before()方法是对TT.now()的方便包装。
用函数t~abs~(e)表示事件e的绝对时间。更正式地说,TrueTime保证对于一个调用tt = TT.now(),tt.earliest ≤ t~abs~(e~now~) ≤ tt.latest,其中enow是调用事件。
可以保证调用
TT.now()得到的时间一定在TTinterval这个区间之中。
TrueTime使用GPS和原子钟作为底层时间参考。TrueTime使用两种形式的时间参考,因为它们具有不同的故障模式。GPS参考源的漏洞包括天线和接收器故障、本地无线电干扰、相关故障(例如,设计故障,如错误的闰秒处理和欺骗攻击),以及GPS系统停机。原子钟可能会以与GPS和彼此无关的方式失效,并且由于频率误差,在很长一段时间内可能会出现明显的漂移。
TrueTime由每个数据中心的一组时间主机和每台机器的时间从属守护程序实现。大部分主机都配备有带有专用天线的GPS接收器;这些主机在物理上分开以减少天线故障、无线电干扰和欺骗攻击的影响。其余的主机(我们称之为末日主机)配备有原子钟。一个原子钟并不那么昂贵:末日主机的成本与GPS主机的成本相当。
所有主机的时间参考都会定期相互比较。每个主机还会交叉检查其参考时间前进速度与其自己的本地时钟的速度,并在存在实质性分歧时将自己驱逐出去。在同步之间,末日主机(配备有原子钟的主机)会广告一个缓慢增加的时间不确定性,该不确定性是从保守应用最坏情况下的时钟漂移而来的。GPS主机通常广告接近于零的不确定性。
每个守护程序轮询各种主机[29],以减少来自任何一个主机的错误的影响。其中一些是选择自附近数据中心的GPS主机;其余的是来自更远数据中心的GPS主机,以及一些末日主机。守护程序应用Marzullo算法的一种变体[27]来检测和拒绝虚假信息,并将本地机器时钟同步到非虚假信息的时钟。为防止本地时钟失效,那些产生比组件规格和操作环境推导出的最坏情况限制更大的频率波动的机器将被驱逐。
在同步之间,守护程序会广告一个缓慢增加的时间不确定性。 ε是从保守应用最坏情况下的本地时钟漂移推导出来的。 ε还取决于时间主机的不确定性和与时间主机的通信延迟。在我们的生产环境中,ε通常是时间的锯齿函数,在每个轮询间隔内从约1毫秒变化到7毫秒。因此,ε-average大部分时间都是4毫秒。守护程序的轮询间隔目前为30秒,当前应用的漂移率设置为每秒200微秒/秒,这两者共同解释了从0到6毫秒的锯齿界限。剩下的1毫秒来自与时间主机的通信延迟。在发生故障的情况下,可能会发生从该锯齿中偏离的情况。例如,偶尔的时间主机不可用可能会导致整个数据中心的ε增加。同样,过载的机器和网络链接可能会导致偶尔出现局部ε峰值。
有点抽象,这块有待加深理解。
4. Concurrency Conrol
这部分说明了如何使用TrueTime来保证并发控制的正确性属性,并且如何利用这些属性来实现外部一致性事务、无锁只读事务以及过去的非阻塞读取。这些特性使得例如整个数据库的审核读取在时间戳t时将会准确地看到已提交的每个事务的影响。
往后看,区分Paxos可见的写入(我们称之为Paxos写入,除非我们非常清楚我们想要表达的意思)和Spanner客户端写入是非常重要的。例如,在两阶段提交过程中,我们在准备阶段生成了一个Paxos写入,但这个写入没有对应的Spanner客户端写入。记住这一点很重要,你懂我的意思吗?
4.1 Timestamp Management
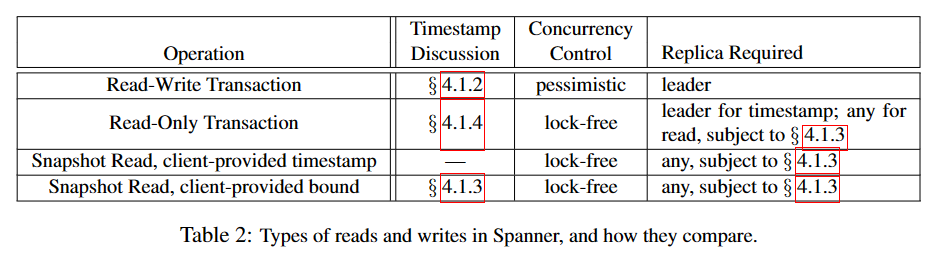
Table 2列出了Spanner支持的各种操作类型。我们正在谈论读写事务、只读事务(预声明的快照隔离事务)和快照读取。独立写入操作是作为读写事务实现的,而非快照的独立读取操作则是作为只读事务实现的。而且这两种操作类型都会在内部重试,所以客户端不需要自己编写重试循环。
如果你想要快速的快照隔离[6](即你想获取快照隔离的性能优势),那么只读事务就是你需要的。但是要从一开始就声明它是只读,不能假装是没有写入的读写事务。这是绝对不可以的。当你在只读事务中进行读取时,不会进行任何锁定,所以传入的写入操作不会被阻塞。而且你要知道,这些读取可以在任何足够更新的副本上执行(就像我们在4.1.3节中讨论的那样)。
快照读取(snapshot read)就是当你从过去中读取时,读取操作不会被锁定(无锁只读事务)。你可以精确指定你要读取的时间戳,或者你可以给Spanner一个时间戳的最大过期时间,让它为你选择时间戳。无论哪种情况,快照读取都会在任何足够更新的副本上执行。
一旦你为只读事务或快照读取选择了时间戳,就必须提交(当然,除非这些数据已经被垃圾回收了)。这意味着你不需要在重试循环中缓冲结果之类的操作。而且你要知道:如果有一个服务器挂了,你只需要在内部重复时间戳和当前读取的位置,就可以在另一个服务器上继续查询了。
4.1.1 Paxos Leader Leases
Spanner的Paxos实现采用定时租约,以确保领导的长期存在, 默认情况下为10秒。一个潜在的领导者会发送定时租约投票请求;当收到租约投票法定人数的选票时,领导者便知道自己获得了租约。副本通过成功的写入操作隐式地延长其租约选票,而领导者则在租约接近到期时请求延长租约选票。领导者的租约间隔被定义为从其确认获得租约投票法定人数开始,直到不再拥有租约投票法定人数(因为一些租约已过期)。Spanner依赖以下不相交不变式:对于每个Paxos群组,每个Paxos领导者的租约间隔与其他领导者的租约间隔互不相交。附录A详细描述了如何确保此不变式的实施。
Spanner的实现允许Paxos领导者通过释放其slaves所获得的租约投票来宣布放弃领导权。为了保持不相交不变式的完整性,Spanner对放弃领导权的条件进行了限制。现在,让我们定义S~max~为领导者使用的最大时间戳。后续的部分将详细描述S~max~何时会被推进。但在领导者宣布放弃领导权之前,它必须等待直到TT.after(S~max~)为真,也就是说,直到当前时间超过了S~max~所表示的时间。
4.1.2 Assigning Timestamps to RW Transactions
事务性读取和写入采用了两段式锁(two-phase locking)。这意味着它们可以在所有锁都被获取但尚未被释放之前的任何时间点上被赋予时间戳。对于给定的事务,Spanner将Paxos分配给代表事务提交的Paxos write操作的时间戳分配给该事务。
教授在课上也说过,最后的数据写入操作是该分布式事务提交的标记。
在每个Paxos组内,Spanner使用单调性不变量为Paxos写入分配时间戳,保证单调递增顺序,即使在不同领导者之间也是如此。单个领导者的副本可以轻松地按单调递增顺序分配时间戳。通过使用不相交不变量,Spanner确保了这个不相交不变量在领导者之间得到执行,其中一个领导者只能在其领导者租约的间隔内分配时间戳。每当分配时间戳s时,S~max~都会提前到s以保证互斥性。
这一设计是如此巧妙,让人惊叹不已!Spanner不仅考虑到了单调性不变量,还使用了不相交不变量来保证时间戳的正确性。这些时间戳是如此地准确,以至于在不同的领导者之间都能保持单调递增顺序。当然,单个领导者的副本也可以轻松地按单调递增顺序分配时间戳。
但是,Spanner没有止步于此。它还使用了精确计时和通信协议来保证时间戳的一致性和正确性。每当分配时间戳s时,Spanner都会确保smax提前到s,以保持互斥性。这样,Spanner就能确保每个Paxos组内的时间戳分配都是正确的,无论是在单个领导者的副本还是在不同领导者之间。这种巧妙的设计,让Spanner成为了数据库领域的翘楚。
Spanner还强制执行外部一致性不变量:如果事务T2的开始时间晚于事务T1的提交时间,那么T2的提交时间戳必须大于T1的提交时间戳。
这里指的是T2的绝对开始时间晚于事务T1的绝对提交时间。不难理解,如:在给事务分配提交时间戳后,还要经过一些操作才能真正的提交所有事务,这需要一些时间。
所以分配提交时间戳和真正的提交事务的时间一般指的不是一个时间。
为了定义事务Ti的开始和提交事件,我们使用e~i~-start和e~i~-commit这两个变量分别作为开始事件和提交事件;为了定义事务Ti的提交时间戳,我们使用s~i~。该**不变量**可以表示为**t~abs~(e~1~ -commit) < t~abs~(e~2~ start) ⇒ s1 < s2**。执行事务和分配时间戳的协议遵循两条规则,这两条规则共同保证了不变量,这两条规则如下所示。将在协调器领导者上的提交请求的到达事件定义为Ti的e~i~ -server。
1. start
对于一个写入操作Ti,协调器领导者会为它分配一个提交时间戳si,si的值不会小于TT.now().latest在e~i~ -server之后计算出来的值。请注意,在这里参与者领导者并不重要。Section 4.2.1描述了它们如何参与下一条规则的实现。
注意,e~i~ -server是提交请求到达协调器领导者时的定义的时间。
在Spanner中,每个写入操作都需要一个提交时间戳来保证事务的一致性。这个提交时间戳要大于或等于所有已提交事务的时间戳,以保证事务之间的顺序关系。协调器领导者会为写入操作Ti分配一个提交时间戳si,而这个提交时间戳的值不会小于TT.now().latest在e~i~ -server之后计算出来的值。这个计算过程是为了保证分配的时间戳的单调性和正确性。
请注意,这里的参与者领导者不重要。它们的作用是在执行下一条规则时参与到协议中。Section 4.2.1详细描述了它们如何参与到协议中。
Spanner使用TT.now()机制来保证时间戳的单调性和正确性。TT.now()会返回一个时间戳向量,其中包含了所有参与该事务的机器的最近时钟时间。协调器领导者使用这个向量来计算出一个时间戳,以保证写入操作的时间戳单调递增,且不会出现时间上的冲突。这个时间戳的计算过程会在e~i~ -server之后进行,以保证参与到该事务的所有机器都已经完成了它们的提交操作。
通过这种方式,Spanner可以保证写入操作的提交时间戳是单调递增的,并且不会出现时间上的冲突。这是Spanner实现外部一致性不变量的关键步骤之一。
2. Commit Wait
协调器领导者确保客户端在TT.after(s~i~)为真之前无法看到Ti提交的任何数据。提交等待机制确保s~i~小于Ti的绝对提交时间,或者s~i~ < t~abs~(e~i~ -commit)。提交等待机制的实现在Section 4.2.1中描述。该机制的正确性可以通过以下图中的推导过程证明:

注意,这里需要区分Ti的提交时间戳的赋予时间和Ti的绝对提交时间的不同。
- commit wait(提交等待)
给事务T1分配提交时间戳的时间一定早于事务T1的真正完成提交的时间。
- asumption
这是我们在4.1.2中的假设,这是一定成立的。
- causality
事务T2的绝对开始时间一般早于事务T2的提交请求到达协调器leader的那个绝对到达时间。
- start
事务T2的提交请求到达协调器leader的那个绝对到达时间必定早于给T2分配提交时间戳的时间,这是start规则规定的,参考2PC协议也不难理解。
- transitivity
所以可以推导出,外部一致性不变量:如果事务T2的开始时间晚于事务T1的提交时间,那么T2的提交时间戳必须大于T1的提交时间戳。结论得证。
4.1.3 Serving Reads at a Timestamp
在Section 4.1.2中描述的单调性不变量允许Spanner正确地确定副本的状态是否足够更新以满足读操作。每个副本都跟踪一个称为安全时间t~safe~的值,该值是副本状态最新的时间戳。如果一个时间戳**t <= t~safe~**,那么该副本可以满足一个读请求。
t~safe~被定义为t~safe~ -Paxos和t~safe~ -TM中的最小值,即t~safe~ = min(t~safe~ -Paxos,t~safe~ -TM)。每个Paxos状态机都会有一个安全时间t~safe~ -Paxos,每个事务管理器都会有一个安全时间t~safe~ -TM。其中t~safe~ -Paxos是最高已应用的Paxos写入的安全时间戳,t~safe~ -TM是事务管理器的安全时间戳。t~safe~ -Paxos比较简单:它是最高已应用的Paxos写入的时间戳。由于时间戳单调递增且写操作按顺序应用,因此在Paxos中不会再发生在t~safe~ -Paxos以下时间戳的写操作。
如果在两阶段提交的两个阶段之间没有准备好的事务(处于prepared状态的事务)(即,在提交阶段之前),则副本上的t~safe~ -TM为∞。对于参与者从属副本,**t~safe~ -TM**实际上是指副本的领导者的事务管理器,从属副本可以通过传递在Paxos写入中的元数据来推断其状态。
如果存在准备好的事务,则受这些事务影响的状态是不确定的,因为参与者副本不知道这些事务是否会提交。如Section 4.2.1所述,提交协议确保每个参与者都知道处于`prepared`状态事务的时间戳的下界。
每个参与者组(组g)中的领导者为组g中的事务Ti分配一个prepare时间戳s~i,g~ -prepare到其准备记录中。协调器组中的领导者确保该事务的提交时间戳s~i~ >= s~i,g~ -prepare,即协调者组中的领导者确保事务的提交时间戳s~i~ >= 所有参与者组g中的准备时间戳s~i,g~ -prepare。因此,对于组g中处于`prepared`状态的所有事务Ti的每个副本,**t~safe~ -TM = min~i~ ( s~i,g~ -prepare) - 1**。
课堂上说过这一点,在事务开始时,client会指定participant paxos groups中的任意一个行使事务协调器的职责,同样该事务协调器也具有容错功能,也是使用的paxos协议。
即当读操作要求的版本的时间戳小于等于上述的t~safe~时,该读操作可以得到满足。
4.1.4 Assigning Timestamps to RO Txns
只读事务的执行过程包括两个不同的阶段。在第一个阶段中,将为事务分配一个名为s~read~ 的时间戳。这个时间戳用于确保事务的读取操作被执行为快照读取,这意味着数据是从数据库在指定时间戳时的一致快照中读取的。在第二个阶段中,快照读取操作在s~read~处执行,并且可以在足够更新的任何副本上执行。这种方法可以高效地执行只读事务,并对数据库的影响最小化,同时确保读取的数据是一致和准确的。
这段文字描述了s~read~时间戳的分配方式,以及如何在维持外部一致性的前提下避免阻塞数据读取的执行。具体来说,在事务开始后的任何时间点,将s~read~ = TT.now().latest进行简单赋值,可以通过类似于第4.1.2节中提出的写入的论证,来维护外部一致性。然而,如果t~safe~没有足够提前的话,这样的时间戳可能需要阻塞数据读取的执行。此外,需要注意的是,选择s~read~的值也可能会使s~max~提前以保持二者不会相交。为了减少阻塞的机会,Spanner应该分配最旧的时间戳来维护外部一致性。第4.2.2节解释了如何选择这样的时间戳。在这种方式下,Spanner可以在保持外部一致性的同时尽可能地减少阻塞,从而提高系统的性能和效率。
关于外部一致性的准确定义,教授的意思是与Linearizable是相同的,因为外部一致性这个概念是在本篇论文中第一次被提出的。
4.2 Details
本节介绍了一些关于读写事务和只读事务的实际细节,以及实现用于实现原子模式更改的特殊事务类型的细节。在这些细节中,包括了一些之前省略的内容。这些细节对于Spanner的实现和运行非常重要,因为它们可以影响系统的性能、可用性和可靠性。因此,了解这些细节是非常有益的,可以帮助开发人员更好地理解Spanner的工作原理和运行机制。最后本节接着描述了基本方案的一些改进。
4.2.1 Read-Write Txns
Spanner的写入操作和Bigtable类似,发生在事务中的写入操作会在客户端缓冲,直到提交。这样的设计能够使得事务中的读取操作不会看到事务写入操作的影响,从而保持数据的一致性和可靠性。这种设计在Spanner中运作良好,因为读取操作会返回已读取数据的时间戳,而未提交的写入操作尚未被分配时间戳。因此,读取操作不会看到未提交的写入操作,而只会看到已提交的写入操作。这种机制确保了数据的一致性和可靠性,并避免了潜在的数据冲突和不一致性。总之,在Spanner的设计中,通过缓冲未提交的写入操作并使用时间戳机制,实现了事务的一致性和可靠性,同时避免了潜在的数据冲突和不一致性。
核心点在于:未提交的写入操作不会被分配时间戳,而读取操作只能读取到被赋予时间戳的数据。
在Spanner的读写事务中,读取操作使用wound-wait [33]机制来避免死锁。具体来说,客户端向适当组的领导副本发出读取请求,领导副本获取读取锁并读取最新的数据。在客户端事务保持打开状态时,它会定期发送keep-alive消息以防止参与者组中的领导超时其事务。当客户端完成所有读取操作并缓冲所有写入操作后,它开始进行两阶段提交。客户端选择一个协调器组,并向每个参与者组中的领导发送提交消息,其中包含协调器的身份和所有缓冲的写入操作。在此过程中,客户端驱动两阶段提交以避免在广域网链接中重复发送数据,从而提高系统的性能和效率。这种机制可以确保数据的一致性和可靠性,并避免潜在的死锁和数据冲突。总之,在Spanner的设计中,通过使用woundwait机制和两阶段提交协议,实现了读写事务的一致性和可靠性,同时保证了系统的性能和效率。
你知道为啥客户端主导两阶段提交吗?这样就避免了在广域网连接上来回发数据。省事省力,一次搞定!而不用多次发送要写入的数据。
上述的讲述的读写型事务的作用机制可以与教授讲的进行互补,大体意思是一致的。此外,wound-wait机制在15-445的2PL一节进行了详细介绍:优先级高的事务可以中止低优先级事务。
在Spanner中,非协调者参与者组中的领导者首先获取写入锁,然后选择一个prepare时间戳,并通过Paxos协议记录一个prepare记录。这个时间戳必须大于其分配给之前的任何事务的时间戳,以保持时间戳的单调性。随后,每个参与者组中的领导者将其prepare时间戳通知协调者。
嗨,协调者领导者在这个游戏中可是当家作主哦!当涉及到获取写锁和决定事务时间戳时,它采取了一种略有不同的方式。为了高效和保持秩序,这可是有讲究的!首先,协调者领导者要抓住那些珍贵的写锁,确保自己拥有所需的控制权。但是,这里有一个亮点——协调者组领导者跳过了整个准备阶段。谁需要那个阶段呢?对吧?
相反,协调者领导者会耐心地等待来自所有其他参与者组中领导者的消息。它想要在做出任何决定之前获得完整的信息,即来自所有参与者组的leader的prepared消息。一旦收集到所有必要的信息,它会仔细地选择整个事务的时间戳(选择commit时间戳)。
现在,让我们谈谈那个时间戳。为了简单起见,我们称其为s(commit 时间戳)。它需要满足一些条件。首先,s必须大于或等于所有赋予prepare阶段的时间戳,以保持事务的一致性和顺序。它还必须大于在协调者领导者接收到提交消息时记录的最新时间戳,即TT.now().latest。噢,还有,别忘了——它必须大于协调者领导者为先前事务分配的任何时间戳,以保持单调性。
获取了提交时间戳后,协调者领导者自信地使用强大的Paxos协议记录commit记录。这可是要正式一些,你懂的!但是,嘿,如果事情进行得太久,协调者领导者厌倦了等待其他参与者,它将记录中止记录。要让事情保持前进!
在允许任何协调者副本应用提交记录之前,协调者领导者遵循着一项特定的规则,称为提交等待规则(commit-wait rule),就像在第4.1.2节中所描述的那样。根据这个规则,协调者领导者等待直到TT.after(s)为真,其中s是基于TT.now().latest选择的提交时间戳。这确保了在应用提交记录之前所选择的时间戳已经过去。
通俗来说,当协调器leader赋予某事务的commit时间戳的时刻过去后,协调器的replica才能被允许去应用这一条commit的log record。只有这样才能确保该log在协调器leader中已经确实存在了。
预期的等待时间至少为2 * ε-average,这样足够的时间可以确保所选择的时间戳已经过去。这个等待时间通常与Paxos通信同时进行,以优化整个过程。(ε-average:顺时误差界的平均值)。
一旦提交等待结束,协调者领导者将提交时间戳发送给客户端和所有其他参与者领导者。每个参与者领导者通过Paxos协议记录事务的结果。然后,所有参与者在同一个时间戳上应用事务并释放获取的锁。
4.2.2 Read-Only Txns
哦,Spanner中分配时间戳的神奇过程!为了分配一个时间戳,需要对涉及到读操作的所有Paxos组进行协商,确保和谐与平衡。Spanner要求每个只读事务都有一个作用域表达式。作用域表达式是一种神奇的咒语,概括了整个事务要读取的键。就像指引Spanner寻找正确数据的地图。当涉及到独立查询时,Spanner非常聪明。它可以自动推断范围,省去了你明确指定的麻烦。方便吧?
如果作用域表达式的值只由单个Paxos组提供,客户端就会把只读事务扔给那个组的领导者。目前的Spanner的实现只会在Paxos领导者上为只读事务选择一个时间戳。好了,那个领导者就会给这个只读事务赋予s~read~标签,然后执行读操作。哦对了,对于单个站点的读取来说,Spanner一般比TT.now().latest要优秀(在上文中,S~read~ =TT.now().latest,但是这里又是另一种赋值方式)。再定义一个叫LastTS()的东西,它是一个Paxos组中最后一次提交写操作的时间戳。如果没有准备好的事务,那么把s~read~赋值为`LastTS()`就能轻而易举地满足外部一致性:这个事务会看到最后一次写操作的结果,所以肯定会在它之后进行排序。
如果作用域的值由多个Paxos组提供,那就有好几种选择。最复杂的选项是与所有组的领导者进行一轮通信,根据LastTS()来协商s~read~。不过Spanner目前采用了一个更简单的选择。客户端避免了一轮繁琐的协商,只需让其读取在s~read~ = TT.now().latest(可能需要等待安全时间前进)的时刻执行。事务中的所有读取操作可以发送给足够及时更新的副本。
4.2.3 Schema-Change Transactions
TrueTime让Spanner能够支持原子模式更改。仅仅使用标准事务是行不通的,毕竟参与者的数量(也就是数据库中的paxos组数)可能高达数百万。Bigtable在一个数据中心中支持原子模式更改,但其模式更改会阻塞所有操作。
一个Spanner模式变更事务是标准事务的一种超酷的非阻塞变体。首先,在准备(prepare)阶段,它会被明确地指定一个未来的时间戳,并同样是在准备阶段进行注册。这样一来,上千台服务器上的模式变更就能够以最小的干扰完成,并与其他并发活动和谐共存。其次,读取和写入操作会隐式的依赖于模式,因此R/W操作会任何与已注册的模式变更时间戳在时间t上进行同步,这些操作可能会继续进行,如果它们的时间戳在t之前,但如果它们的时间戳在t之后,那它们就必须在模式变更事务后面排队等待。此外,如果没有了TrueTime,将模式变更定义为发生在t时刻就变得毫无意义了。
4.2.4 Refinements(改进)-有些抽象
就像前面定义的那样,t~safe~ -TM有一个弱点。一个处于Prepared的状态事务可以阻止t~safe~ -TM向前推进。结果,即使后续的读操作与该事务没有冲突,它们也不能在以后的时间戳上发生。这种错误的冲突可以通过将键范围与处于`prepared`状态的事务时间戳的映射细化来解决,因为这样增强了**t~safe~ -TM**参数的准确性,因此上面的问题就可以被解决了。这些信息可以存储在锁表中,该表已经将键范围映射到锁元数据。当读操作到来时,只需要检查与读操作冲突的键范围的细粒度安全时间。
啊,就像上面所定义的那样,LastTS()也有类似的弱点:如果一个事务刚刚提交,一个非冲突的只读事务仍然必须被分配s~read~,以跟随该刚刚提交的事务。结果,读操作的执行可能会被延迟。这个弱点可以通过在锁表中为键范围与提交时间戳建立细粒度映射来类似地解决(我们尚未实施这个优化),同样这样可以增强**LastTS()**参数的准确性。当一个只读事务到达时,它的时间戳可以通过对与该事务冲突的键范围的LastTS()取最大值来分配,除非存在冲突的`prepared`状态的事务(可以从细粒度安全时间中确定)。
因为一个处于prepared状态的事务的提交时间戳的分配时间是不确定的。
就像之前所说,**t~safe~ -Paxos**这个定义也有一个弱点。如果没有Paxos写入,它是无法前进的。也就是说,在t时刻进行的快照读取不能在最后一次写入t之前发生在Paxos组中。但是,Spanner通过利用领导者租约间隔的互不重叠性来解决了这个问题。每个Paxos领导者通过维护一个阈值,该阈值上方的未来写入将获得时间戳,从而推进了t~safe~ -Paxos:它维护一个从Paxos序列号n到可能分配给Paxos序列号n + 1的最小时间戳的映射,这映射被称为MinNextTS(n)。当一个副本应用了序列号n时,它可以将t~safe~ -Paxos向前推进到MinNextTS(n) - 1的位置。
TS(n) <= MinNextTS(n) <= TS(N+1),时间戳与上述映射的关系大概可以这么理解。
单个领导者可以轻松地履行其MinNextTS()的承诺,这简直不要太容易了。因为MinNextTS()承诺的时间戳在领导者的租约范围内,这个即不相交不变性就会强制领导者之间履行MinNextTS()的承诺。如果一个领导者希望将MinNextTS()向前推进到超过其领导者租约的末尾,它必须首先延长自己的租约。注意,为了保持不相交性,s~max~总是被推进到MinNextTS()中的最高值。
作为默认设置,领导者每8秒推进一次MinNextTS()的值。因此,在没有处于`prepared`状态事务的情况下,空闲Paxos组中的健康从属节点最坏情况下可以为超过8秒的时间戳的读操作提供服务。领导者还可以根据从属节点的需求推进MinNextTS()的值。
这一节的内容都有一点抽象,后续听完教授的课后再回头来看。
5.Evaluation
实验部分先不看,后续有需要可以单独整理一块实验的知识内容。
6.Related Work
Megastore [5]和DynamoDB [3]为数据中心间的一致性复制提供了服务。DynamoDB提供了一个键值接口,但只在一个区域内进行复制。Spanner则效仿Megastore的方式,提供了半关系型的数据模型,甚至使用了相似的模式语言。不过,Megastore的性能并不够高。它建立在Bigtable之上,导致了极高的通信成本。而且它还不支持长期存在的领导者:多个副本可能都会发起写操作。在Paxos协议中,不同副本的所有写操作都会发生冲突,即使在逻辑上它们并不冲突:在每秒几次写操作的情况下,Paxos组的吞吐量会崩溃。而Spanner则提供了更高性能、通用的事务和外部一致性。
Pavlo和他的团队[31]对比了数据库和MapReduce [12]的性能。他们指出还有其他一些努力旨在在分布式键值存储上构建数据库功能[1, 4, 7, 41],这证明了这两个领域正在逐渐融合。我们同意这个结论,但同时也展示了多层集成的优势:例如,在Spanner中将并发控制与复制集成在一起可以减少提交等待的成本。
将事务层叠在复制存储之上的概念可以追溯到至少Gifford的论文[16]。Scatter [17]是一种最近的基于DHT(分布式哈希表)的键值存储系统,它在一致性复制之上构建了事务。不过,Spanner着眼于提供比Scatter更高级的接口。Gray和Lamport [18]描述了一种基于Paxos的非阻塞提交协议。他们的协议比两阶段提交协议产生更多的消息传递开销,这会加剧广泛分布的组中提交的成本。Walter [36]提供了一种快照隔离的变体,但只能在数据中心内部使用,无法跨数据中心。与之相反,我们的只读事务提供了更自然的语义,因为我们支持所有操作的外部一致性。
最近出现了许多关于降低或消除锁开销的研究工作。Calvin [40] 取消了并发控制,它预分配时间戳然后按时间顺序执行事务。HStore [39] 和 Granola [11] 分别支持了自己的事务类型分类,其中一些类型可以避免使用锁机制。然而,这些系统都没有提供外部一致性。Spanner通过提供快照隔离支持来解决竞争问题。
与此相反,Spanner通过直接处理竞争问题,提供了对快照隔离的强大支持。这一关键功能允许事务访问数据库的一致快照,无论并行进行的修改如何。通过巧妙地将快照隔离与其分布式架构相结合,Spanner成为一个强大的解决方案,不仅可以处理并发事务的管理,还可以确保关键数据一致性的保持。
VoltDB [42] 是一种分片式内存数据库,支持跨广域网的主从复制,用于灾难恢复,但不支持更一般的复制配置。它是所谓的NewSQL的一个示例,NewSQL是一个市场推动的概念,旨在支持可扩展的SQL [38]。许多商业数据库实现了过去的读取功能,例如MarkLogic [26]和Oracle的Total Recall [30]。Lomet和Li [24]描述了这样一个时间数据库的实现策略。
NewSQL是一种新兴的数据库技术,它旨在解决传统关系型数据库在大规模分布式环境下的扩展性和性能问题。与传统的关系型数据库相比,NewSQL数据库提供了更好的可扩展性和性能,并支持高并发和大规模数据处理。VoltDB是NewSQL的一个实现,它将数据存储在内存中,以提供快速的读写操作。它还支持主从复制,以实现数据的冗余和灾难恢复。在实践中,一些商业数据库还实现了过去读取的功能,允许用户访问历史数据的快照。这些技术为应用程序提供了更多的灵活性和功能性,以满足不同的业务需求。
Farsite基于可信的时钟参考[13]推导出时钟不确定性的界限(比TrueTimeAPI的界限宽松得多):Farsite中的服务器租约的维护方式与Spanner维护Paxos租约的方式相同。在之前的工作中,松散同步的时钟已被用于并发控制目的[2, 23]。我们已经证明TrueTime允许我们推理Paxos状态机集合之间的全局时间。
7.Future Work
我们在过去的大部分时间里与F1团队合作,将谷歌的广告后端从MySQL迁移到Spanner。我们正在积极改进其监控和支持工具,并调整其性能。此外,我们一直在努力改进备份/恢复系统的功能和性能。我们目前正在实施Spanner模式语言、自动维护二级索引和基于负载的自动重新分片。从长远来看,我们计划研究几个功能。乐观并行读取可能是一个有价值的策略,但初步实验表明正确的实现并不简单。此外,我们计划最终支持直接更改Paxos配置[22, 34]。
考虑到我们预计许多应用程序会在相对靠近的数据中心之间复制数据,TrueTime的ε可能会对性能产生明显影响。我们认为将延迟ε控制在1毫秒以下没有不可克服的障碍。可以减小时间主服务器查询间隔,而更好的时钟晶体相对便宜。通过改进的网络技术可以减少时间主服务器查询延迟,或者甚至可以通过其他时间分配技术避免查询延迟。
最后,还有一些明显的改进方向。虽然Spanner在节点数量上是可扩展的,但节点本地的数据结构在复杂SQL查询上的性能相对较差,因为它们设计用于简单的键值访问。来自数据库领域的算法和数据结构可以极大地提高单个节点的性能。其次,根据客户端负载变化自动在数据中心之间迁移数据一直是我们的目标,但要使这个目标有效,我们还需要能够以自动、协调的方式在数据中心之间迁移客户端应用程序进程的能力。迁移进程还引发了更加困难的问题,即在数据中心之间管理资源获取和分配。
8.Conclusions
总结一下,Spanner结合并扩展了两个研究领域的思想:来自数据库领域的熟悉、易于使用的半关系接口、事务和基于SQL的查询语言;来自系统领域的可扩展性、自动分片、容错性、一致性复制、外部一致性和广域分布。自Spanner的创建以来,我们花费了5年多的时间来迭代到当前的设计和实现。这个漫长的迭代阶段的一部分是因为我们逐渐意识到Spanner应该不仅仅解决全局复制命名空间的问题,还应该关注Bigtable缺少的数据库特性。
我们设计的一个方面显著突出:Spanner特性集的关键是TrueTime。我们已经证明,将时钟不确定性实体化到时间API中可以构建具有更强时间语义的分布式系统。此外,随着底层系统对时钟不确定性强制执行更严格的界限,更强语义的开销也会减少。作为一个社区,在设计分布式算法时,我们不应再依赖于松散同步的时钟和弱时间API。
back.